

代码拉取完成,页面将自动刷新
同步操作将从 turnon/blog 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
title: 流量控制
date: 2020-01-20 11:06:00
categories:
- 分布式
- 分布式调度
tags:
- 分布式
- 流量调度
- 流量控制
- 限流
- 熔断
- 降级
permalink: /pages/60bb6d/
在高并发场景下,为了应对瞬时海量请求的压力,保障系统的平稳运行,必须预估系统的流量阈值,通过限流规则阻断处理不过来的请求。
限流可以认为是服务降级的一种。限流就是限制系统的输入和输出流量已达到保护系统的目的。一般来说系统的吞吐量是可以被测算的,为了保证系统的稳定运行,一旦达到的需要限制的阈值,就需要限制流量并采取一些措施以完成限制流量的目的。比如:延迟处理,拒绝处理,或者部分拒绝处理等等。
限流规则包含三个部分:时间粒度,接口粒度,最大限流值。限流规则设置是否合理直接影响到限流是否合理有效。
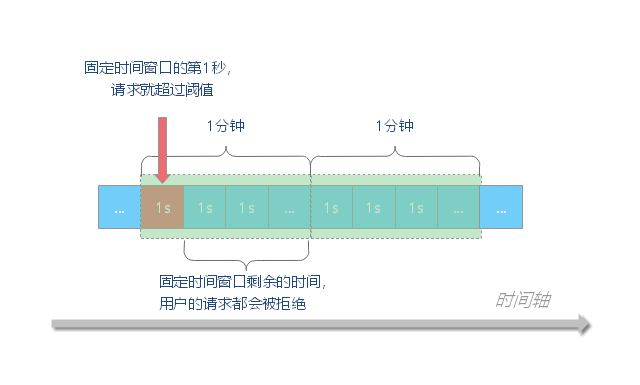
计数器法的原理是:设置一个计数器,用于统计指定时间段内的请求数量,并在指定时间段之后重置计数器。在这个过程中,如果请求量超过限定的阈值,则拒绝请求。
这种算法的缺陷是:这种算法是针对一个时间段进行统计,如果请求分布不均匀,极端情况下,所有请求都在某一刻收到,还是可能压垮系统。例如,假设我们限流规则为每秒钟不超过 100 次接口请求,第一个 1s 时间窗口内,100 次接口请求都集中在最后的 10ms 内,在第二个 1s 的时间窗口内,100 次接口请求都集中在最开始的 10ms 内,虽然两个时间窗口内流量都符合限流要求,但是在这两个时间窗口临界的 20ms 内会集中有 200 次接口请求,如果不做限流,集中在这 20ms 内的 200 次请求就有可能压垮系统。
【示例】使用 AtomicInteger 实现计数器法
public class Counter {
/**
* 最大访问数量
*/
private final int limit = 10;
/**
* 访问时间差
*/
private final long timeout = 1000;
/**
* 请求时间
*/
private long time;
/**
* 当前计数器
*/
private AtomicInteger reqCount = new AtomicInteger(0);
public boolean limit() {
long now = System.currentTimeMillis();
if (now < time + timeout) {
// 单位时间内
reqCount.addAndGet(1);
return reqCount.get() <= limit;
} else {
// 超出单位时间
time = now;
reqCount = new AtomicInteger(0);
return true;
}
}
}
【示例】基于 Redis Lua 计数限流算法的实现
-- 实现原理
-- 每次请求都将当前时间,精确到秒作为 key 放入 Redis 中,超时时间设置为 2s, Redis 将该 key 的值进行自增
-- 当达到阈值时返回错误,表示请求被限流
-- 写入 Redis 的操作用 Lua 脚本来完成,利用 Redis 的单线程机制可以保证每个 Redis 请求的原子性
-- 资源唯一标志位
local key = KEYS[1]
-- 限流大小
local limit = tonumber(ARGV[1])
-- 获取当前流量大小
local currentLimit = tonumber(redis.call('get', key) or "0")
if currentLimit + 1 > limit then
-- 达到限流大小 返回
return 0;
else
-- 没有达到阈值 value + 1
redis.call("INCRBY", key, 1)
-- 设置过期时间
redis.call("EXPIRE", key, 2)
return currentLimit + 1
end
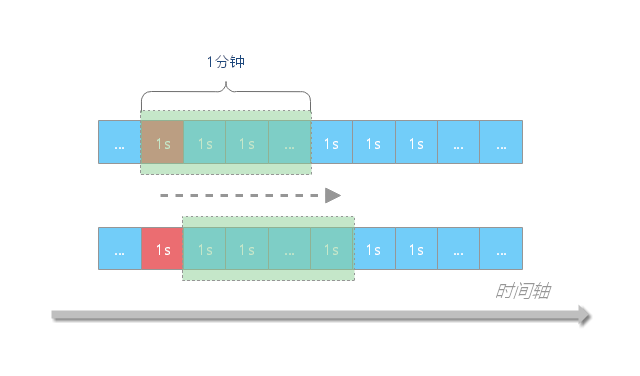
滑动窗口法的原理:
滑动窗口法是计数器算法的一种改进,增加一个时间粒度的度量单位,将原来的一个时间窗口划分成多个时间窗口,并且不断向右滑动该窗口。流量经过滑动时间窗口算法整形之后,可以保证任意时间窗口内,都不会超过最大允许的限流值,从流量曲线上来看会更加平滑,可以部分解决上面提到的临界突发流量问题。
对比固定时间窗口限流算法,滑动时间窗口限流算法的时间窗口是持续滑动的,并且除了需要一个计数器来记录时间窗口内接口请求次数之外,还需要记录在时间窗口内每个接口请求到达的时间点,对内存的占用会比较多。 在临界位置的突发请求都会被算到时间窗口内,因此可以解决计数器算法的临界问题,
比如在上文的例子中,通过滑动窗口算法整型后,第一个 1s 的时间窗口的 100 次请求都会通过,第二个时间窗口最开始的 10ms 内的 100 个请求都会被限流熔断。
滑动窗口法的缺陷:基于时间窗口的限流算法,只能在选定的时间粒度上限流,对选定时间粒度内的更加细粒度的访问频率不做限制。
import java.util.Iterator;
import java.util.Random;
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.stream.IntStream;
public class TimeWindow {
private ConcurrentLinkedQueue<Long> queue = new ConcurrentLinkedQueue<Long>();
/**
* 间隔秒数
*/
private int seconds;
/**
* 最大限流
*/
private int max;
public TimeWindow(int max, int seconds) {
this.seconds = seconds;
this.max = max;
/**
* 永续线程执行清理queue 任务
*/
new Thread(() -> {
while (true) {
try {
// 等待 间隔秒数-1 执行清理操作
Thread.sleep((seconds - 1) * 1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
clean();
}
}).start();
}
public static void main(String[] args) throws Exception {
final TimeWindow timeWindow = new TimeWindow(10, 1);
// 测试3个线程
IntStream.range(0, 3).forEach((i) -> {
new Thread(() -> {
while (true) {
try {
Thread.sleep(new Random().nextInt(20) * 100);
} catch (InterruptedException e) {
e.printStackTrace();
}
timeWindow.take();
}
}).start();
});
}
/**
* 获取令牌,并且添加时间
*/
public void take() {
long start = System.currentTimeMillis();
try {
int size = sizeOfValid();
if (size > max) {
System.err.println("超限");
}
synchronized (queue) {
if (sizeOfValid() > max) {
System.err.println("超限");
System.err.println("queue中有 " + queue.size() + " 最大数量 " + max);
}
this.queue.offer(System.currentTimeMillis());
}
System.out.println("queue中有 " + queue.size() + " 最大数量 " + max);
}
}
public int sizeOfValid() {
Iterator<Long> it = queue.iterator();
Long ms = System.currentTimeMillis() - seconds * 1000;
int count = 0;
while (it.hasNext()) {
long t = it.next();
if (t > ms) {
// 在当前的统计时间范围内
count++;
}
}
return count;
}
/**
* 清理过期的时间
*/
public void clean() {
Long c = System.currentTimeMillis() - seconds * 1000;
Long tl = null;
while ((tl = queue.peek()) != null && tl < c) {
System.out.println("清理数据");
queue.poll();
}
}
}
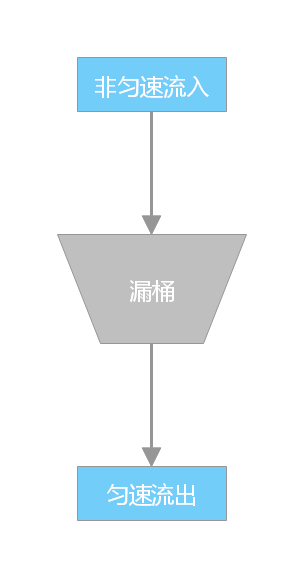
漏桶算法内部有一个容器,当请求进来时,相当于水倒入漏斗,然后从下端小口慢慢匀速的流出。不管上面流量多大,下面流出的速度始终保持不变。
漏桶算法的本质是,不管理请求量有多大,处理请求的速度始终是固定的。这种模式类似生活中的漏斗,上宽下窄。请求进来的速度是未知的,可能突然进来很多请求,没来得及处理的请求就先放在漏斗里。漏斗本身也有容量上限,如果桶满了,那么新进来的请求就丢弃。
漏桶算法的优点是:这种策略的好处是,做到了流量整形,即无论流量多大,即便是突发的大流量,输出依旧是一个稳定的流量。
漏桶算法的缺点是:无法应对短时间的突刺流量。
漏桶策略适用于间隔性突发流量且流量不用即时处理的场景。
【示例】漏桶法实现
public class LeakBucket {
/**
* 时间
*/
private long time;
/**
* 总量
*/
private Double total;
/**
* 水流出去的速度
*/
private Double rate;
/**
* 当前总量
*/
private Double nowSize;
public boolean limit() {
long now = System.currentTimeMillis();
nowSize = Math.max(0, (nowSize - (now - time) * rate));
time = now;
if ((nowSize + 1) < total) {
nowSize++;
return true;
} else {
return false;
}
}
}
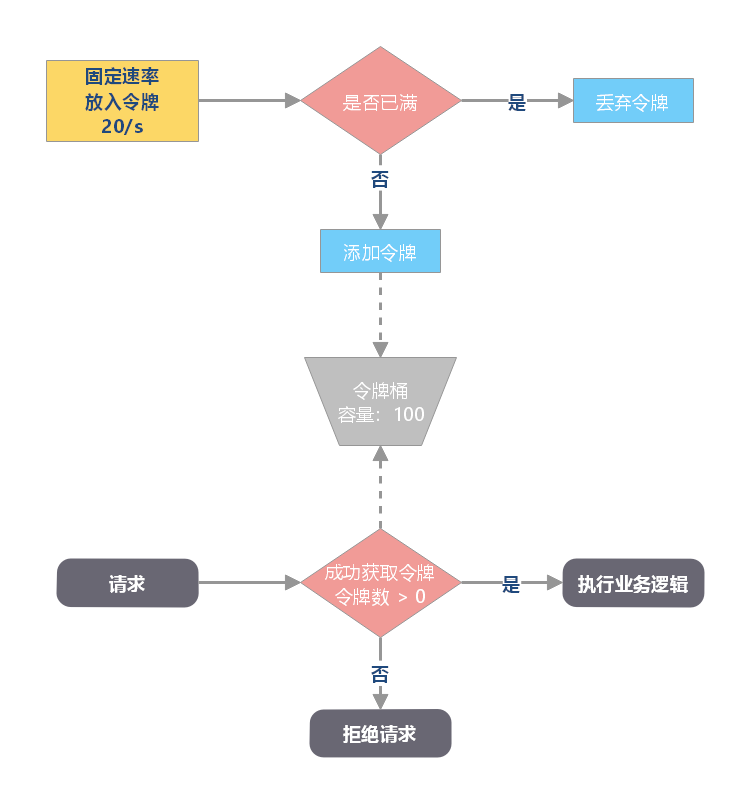
令牌桶算法的原理:
因为令牌桶存放了很多令牌,那么大量的突发请求会被执行,但是它不会出现临界问题,在令牌用完之后,令牌是以一个恒定的速率添加到令牌桶中的,因此不能再次发送大量突发请求。
规定固定容量的桶,token 以固定速度往桶内填充,当桶满时 token 不会被继续放入,每过来一个请求把 token 从桶中移除,如果桶中没有 token 不能请求。
令牌桶算法适用于有突发特性的流量,且流量需要即时处理的场景。
【示例】Java 实现令牌桶算法
public class TokenBucket {
/**
* 时间
*/
private long time;
/**
* 总量
*/
private Double total;
/**
* token 放入速度
*/
private Double rate;
/**
* 当前总量
*/
private Double nowSize;
public boolean limit() {
long now = System.currentTimeMillis();
nowSize = Math.min(total, nowSize + (now - time) * rate);
time = now;
if (nowSize < 1) {
// 桶里没有token
return false;
} else {
// 存在token
nowSize -= 1;
return true;
}
}
}
【示例】基于 Redis Lua 令牌桶限流算法实现
-- 令牌桶限流
-- 令牌的唯一标识
local bucketKey = KEYS[1]
-- 上次请求的时间
local last_mill_request_key = KEYS[2]
-- 令牌桶的容量
local limit = tonumber(ARGV[1])
-- 请求令牌的数量
local permits = tonumber(ARGV[2])
-- 令牌流入的速率
local rate = tonumber(ARGV[3])
-- 当前时间
local curr_mill_time = tonumber(ARGV[4])
-- 添加令牌
-- 获取当前令牌的数量
local current_limit = tonumber(redis.call('get', bucketKey) or "0")
-- 获取上次请求的时间
local last_mill_request_time = tonumber(redis.call('get', last_mill_request_key) or "0")
-- 计算向桶里添加令牌的数量
if last_mill_request_time == 0 then
-- 令牌桶初始化
-- 更新上次请求时间
redis.call("HSET", last_mill_request_key, curr_mill_time)
return 0
else
local add_token_num = math.floor((curr_mill_time - last_mill_request_time) * rate)
end
-- 更新令牌的数量
if current_limit + add_token_num > limit then
current_limit = limit
else
current_limit = current_limit + add_token_num
end
redis.pcall("HSET",bucketKey, current_limit)
-- 设置过期时间
redis.call("EXPIRE", bucketKey, 2)
-- 限流判断
if current_limit - permits < 1 then
-- 达到限流大小
return 0
else
-- 没有达到限流大小
current_limit = current_limit - permits
redis.pcall("HSET", bucketKey, current_limit)
-- 设置过期时间
redis.call("EXPIRE", bucketKey, 2)
-- 更新上次请求的时间
redis.call("HSET", last_mill_request_key, curr_mill_time)
end
前面介绍了限流算法的基本原理和一些简单的实现。但在生产环境,我们一般应该使用更成熟的限流工具。
RateLimiter:RateLimiter 基于漏桶算法,但它参考了令牌桶算法。具体用法可以参考:RateLimiter 基于漏桶算法,但它参考了令牌桶算法
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。





