

代码拉取完成,页面将自动刷新
All true classification is genealogical.
—CHARLES DARWIN, 《The Origin of Species》
一切真实的分类都是依据家系的 - 达尔文,《物种起源》
It is difficult, if not impossible, for anyone to learn a subject purely by reading about it, without applying the information to specific problems and thereby forcing himself to think about what has been read. Furthermore, we all learn best the things that we have discovered ourselves.
— DONALD KNUTH, 《The Art of Computer Programming》
学而不能时习之, 就很难学精通。 纯粹通过阅读来学习一门学科,缺乏具体的应用场景,也就很难促使自己进行思考。 也就是说, 自己悟透的才理解最深入。
— 高德纳, 《计算机程序设计艺术》
| Authors: Ceki Gülcü, Sébastien Pennec, Carl Harris Copyright © 2000-2017, QOS.ch | |
|---|---|
| This document is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 2.5 License |
Logback's basic architecture is sufficiently generic so as to apply under different circumstances. At the present time, logback is divided into three modules, logback-core, logback-classic and logback-access.
Logback的基本结构十分通用,足以应对各种不同的场景。 当前的logback分为: logback-core, logback-classic 和 logback-access 三个模块。
The core module lays the groundwork for the other two modules. The classic module extends core. The classic module corresponds to a significantly improved version of log4j. Logback-classic natively implements the SLF4J API so that you can readily switch back and forth between logback and other logging systems such as log4j or java.util.logging (JUL) introduced in JDK 1.4. The third module called access integrates with Servlet containers to provide HTTP-access log functionality. A separate document covers access module documentation.
logback-core 模块是其他两个模块的基础。
logback-classic 扩展了核心模块。 相当于是 log4j 的优化版。 Logback-classic 内置实现了 SLF4J API,可以在logback和其他日志框架之间轻松迁移(例如log4j, JDK1.4引入的 java.util.logging(JUL)等)。
logback-access 是第三个模块, 用于和Servlet容器集成,提供 HTTP-access 日志功能。 这个模块有单独的文档: access 模块文档。
In the remainder of this document, we will write "logback" to refer to the logback-classic module.
在接下来的内容中,使用 “logback” 来表示 logback-classic 模块。
Logback is built upon three main classes: Logger, Appender and Layout. These three types of components work together to enable developers to log messages according to message type and level, and to control at runtime how these messages are formatted and where they are reported.
Logback 有三个主要的基础类: Logger, Appender 以及 Layout。 这三种类型的组件协同工作,使开发人员可以通过消息类型(message type)和级别(level)来打印不同的日志消息,并确定日志消息的格式, 以及打印到哪些地方。
The Logger class is part of the logback-classic module. On the other hand, the Appender and Layout interfaces are part of logback-core. As a general-purpose module, logback-core has no notion of loggers.
Logger 是logback-classic模块中的一个类。
而 Appender 和 Layout 接口则是 logback-core 的一部分。
logback-core 作为通用模块,是没有记录器(logger)这个概念的。
The first and foremost advantage of any logging API over plain System.out.println resides in its ability to disable certain log statements while allowing others to print unhindered. This capability assumes that the logging space, that is, the space of all possible logging statements, is categorized according to some developer-chosen criteria. In logback-classic, this categorization is an inherent part of loggers. Every single logger is attached to a LoggerContext which is responsible for manufacturing loggers as well as arranging them in a tree like hierarchy.
与纯粹的 System.out.println 相比, 各种日志框架API都支持一个重要的功能: 禁用符合某些特征的日志, 同时其他日志能够正常打印。
实现这种功能需要有一个前提,日志命名空间(logging space), 对所有的日志按照某种标准进行归类。
在 logback-classic 中,这种归类是 logger 内置的。 将每个logger都加入LoggerContext中,LoggerContext 主要负责将 loggers 维护成一棵树状的结构。
Loggers are named entities. Their names are case-sensitive and they follow the hierarchical naming rule:
Logger 是一种有名字的实体。而且它们的名称(name)区分大小写, 遵循分层命名规则:
Named Hierarchy
A logger is said to be an ancestor of another logger if its name followed by a dot is a prefix of the descendant logger name. A logger is said to be a parent of a child logger if there are no ancestors between itself and the descendant logger.
分层命名
如果
loggerS实例对应的name加上一个点(.),是另一个loggerS实例对应name的前缀, 则称loggerP是loggerS的祖先/上级(ancestor)。 如果loggerP与loggerS之间没有其他层级,则称loggerP是loggerS的父级/上级(parent)。
For example, the logger named "com.foo" is a parent of the logger named "com.foo.Bar". Similarly, "java" is a parent of "java.util" and an ancestor of "java.util.Vector". This naming scheme should be familiar to most developers.
例如,名为 "com.foo" 的logger, 是名为"com.foo.Bar"的logger的上级。
同样,"java"是"java.util"的上级,也是"java.util.Vector"的上级。大部分开发人员应该很熟悉这种命名方案。
The root logger resides at the top of the logger hierarchy. It is exceptional in that it is part of every hierarchy at its inception. Like every logger, it can be retrieved by its name, as follows:
根记录器(root logger)位于记录器层次结构的顶部。 这是一项特殊设定,从一开始就是这样定义的。
在代码中, 可以像获取普通Logger一样,按名称获取跟记录器,如下所示:
Logger rootLogger = LoggerFactory.getLogger(org.slf4j.Logger.ROOT_LOGGER_NAME);
All other loggers are also retrieved with the class static getLogger method found in the org.slf4j.LoggerFactory class. This method takes the name of the desired logger as a parameter. Some of the basic methods in the Logger interface are listed below.
其他的记录器也可以通过 org.slf4j.LoggerFactory 类中的 static 方法 getLogger 获取。 此方法接收所需记录器的名称。 下面列出了Logger接口中定义的一些基本方法。
package org.slf4j;
public interface Logger {
// Printing methods:
public void trace(String message);
public void debug(String message);
public void info(String message);
public void warn(String message);
public void error(String message);
}
Loggers may be assigned levels. The set of possible levels (TRACE, DEBUG, INFO, WARN and ERROR) are defined in the ch.qos.logback.classic.Level class. Note that in logback, the Level class is final and cannot be sub-classed, as a much more flexible approach exists in the form of Marker objects.
可以在配置中为Logger指定级别。 可选的日志级别包括(TRACE, DEBUG, INFO, WARN and ERROR), 在 ch.qos.logback.classic.Level 类中定义。 请注意,在logback中,Level是final类,不能被继承,所以可以通过标记(Marker)对象的方式来配置。
If a given logger is not assigned a level, then it inherits one from its closest ancestor with an assigned level. More formally:
如果某个Logger没有明确指定日志级别,则会从最近的上级继承。 具体为:
The effective level for a given logger
L, is equal to the first non-null level in its hierarchy, starting atLitself and proceeding upwards in the hierarchy towards the root logger.
记录器
L的有效级别, 等于其层次结构中的第一个非空的日志级别, 从L自身开始往上遍历,一直找到 root logger 为止。
To ensure that all loggers can eventually inherit a level, the root logger always has an assigned level. By default, this level is DEBUG.
为了确保所有记录器都可以继承到日志级别,根记录器一定要有日志级别。 默认是DEBUG。
Below are four examples with various assigned level values and the resulting effective (inherited) levels according to the level inheritance rule.
下面的四个示例,指定了不同的日志级别, 并列举出继承得到的生效日志级别。
Example 1
| Logger name | Assigned level | Effective level |
|---|---|---|
| root | DEBUG | DEBUG |
| X | DEBUG | |
| X.Y | DEBUG | |
| X.Y.Z | DEBUG |
In example 1 above, only the root logger is assigned a level. This level value, DEBUG, is inherited by the other loggers X, X.Y and X.Y.Z
在示例1中,只指定了根记录器的日志级别 DEBUG。 其他记录器 X, X.Y 和 X.Y.Z 都继承了这个级别。
Example 2
| Logger name | Assigned level | Effective level |
|---|---|---|
| root | ERROR | ERROR |
| X | INFO | INFO |
| X.Y | DEBUG | DEBUG |
| X.Y.Z | WARN | WARN |
In example 2 above, all loggers have an assigned level value. Level inheritance does not come into play.
在示例2中,所有记录器都指定了日志级别。 所以这里的日志级别继承没有起作用。
Example 3
| Logger name | Assigned level | Effective level |
|---|---|---|
| root | DEBUG | DEBUG |
| X | INFO | INFO |
| X.Y | INFO | |
| X.Y.Z | ERROR | ERROR |
In example 3 above, the loggers root, X and X.Y.Z are assigned the levels DEBUG, INFO and ERROR respectively. Logger X.Y inherits its level value from its parent X.
在示例3中,分别为记录器 root, X 和 X.Y.Z 指定了 DEBUG, INFO, ERROR级别。 记录器 X.Y 从上级 X 继承了日志级别。
Example 4
| Logger name | Assigned level | Effective level |
|---|---|---|
| root | DEBUG | DEBUG |
| X | INFO | INFO |
| X.Y | INFO | |
| X.Y.Z | INFO |
In example 4 above, the loggers root and X and are assigned the levels DEBUG and INFO respectively. The loggers X.Y and X.Y.Z inherit their level value from their nearest parent X, which has an assigned level.
在示例4中,分别为记录器root, X指定了 DEBUG, INFO级别。 记录器 X.Y 和 X.Y.Z 从其最近的上级 X 继承了日志级别。
By definition, the printing method determines the level of a logging request. For example, if L is a logger instance, then the statement L.info("..") is a logging statement of level INFO.
根据定义,打印方法决定了日志的级别。 例如,如果 L 是logger实例,则 L.info("..") 语句输出INFO级别的日志。
A logging request is said to be enabled if its level is higher than or equal to the effective level of its logger. Otherwise, the request is said to be disabled. As described previously, a logger without an assigned level will inherit one from its nearest ancestor. This rule is summarized below.
如果日志请求的级别高于或等于logger的有效级别,则称该日志请求为“已启用”(enabled)。 否则,该请求被称为“已禁用”(disabled)。 如前所述,没有分配级别的 logger 将从其最近的祖先那里继承。该规则总结如下。
Basic Selection Rule
A log request of level p issued to a logger having an effective level q, is enabled if p >= q.
基本选择规则
如果
p>=q,则有效级别为 q 的记录器的级别 p 的日志请求。
This rule is at the heart of logback. It assumes that levels are ordered as follows: TRACE < DEBUG < INFO < WARN < ERROR.
这是 logback 的核心规则。 预定义的级别顺序为:TRACE < DEBUG < INFO < WARN < ERROR。
In a more graphic way, here is how the selection rule works. In the following table, the vertical header shows the level of the logging request, designated by p, while the horizontal header shows effective level of the logger, designated by q. The intersection of the rows (level request) and columns (effective level) is the boolean resulting from the basic selection rule.
下面是选择规则的实现原理的图形化表示。 在下表中,垂直标题显示记录请求的级别,由 p 表示,而水平标题显示记录器的有效级别,由 q 表示。行(级别请求)和列(有效级别)的交集是基本选择规则产生的布尔值。
| level of request p | effective level q | |||||
|---|---|---|---|---|---|---|
| TRACE | DEBUG | INFO | WARN | ERROR | OFF | |
| TRACE | YES | NO | NO | NO | NO | NO |
| DEBUG | YES | YES | NO | NO | NO | NO |
| INFO | YES | YES | YES | NO | NO | NO |
| WARN | YES | YES | YES | YES | NO | NO |
| ERROR | YES | YES | YES | YES | YES | NO |
Here is an example of the basic selection rule.
以下代码演示基本的选择规则。
import ch.qos.logback.classic.Level;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
....
// get a logger instance named "com.foo". Let us further assume that the
// logger is of type ch.qos.logback.classic.Logger so that we can
// set its level
ch.qos.logback.classic.Logger logger =
(ch.qos.logback.classic.Logger) LoggerFactory.getLogger("com.foo");
//set its Level to INFO. The setLevel() method requires a logback logger
logger.setLevel(Level.INFO);
Logger barlogger = LoggerFactory.getLogger("com.foo.Bar");
// This request is enabled, because WARN >= INFO
logger.warn("Low fuel level.");
// This request is disabled, because DEBUG < INFO.
logger.debug("Starting search for nearest gas station.");
// The logger instance barlogger, named "com.foo.Bar",
// will inherit its level from the logger named
// "com.foo" Thus, the following request is enabled
// because INFO >= INFO.
barlogger.info("Located nearest gas station.");
// This request is disabled, because DEBUG < INFO.
barlogger.debug("Exiting gas station search");
Calling the LoggerFactory.getLogger method with the same name will always return a reference to the exact same logger object.
使用相同的name调用LoggerFactory.getLogger方法,将会返回同一个logger对象。
For example, in
示例:
Logger x = LoggerFactory.getLogger("wombat");
Logger y = LoggerFactory.getLogger("wombat");
x and y refer to exactly the same logger object.
x 和 y 指向同一个logger对象。
Thus, it is possible to configure a logger and then to retrieve the same instance somewhere else in the code without passing around references. In fundamental contradiction to biological parenthood, where parents always precede their children, logback loggers can be created and configured in any order. In particular, a "parent" logger will find and link to its descendants even if it is instantiated after them.
因此,可以配置logger,然后在其他代码中获取相同的实例,而无需传递logger引用。 现实世界中总是现有父母再有孩子,但logback支持任意顺序创建和配置logger。 特别是,"parent" logger将查找并链接到其后代,即使在后面实例化。
Configuration of the logback environment is typically done at application initialization. The preferred way is by reading a configuration file. This approach will be discussed shortly.
对logback环境的配置通常在应用程序初始化时完成。 首选读取配置文件。稍后将讨论这种方法。
Logback makes it easy to name loggers by software component. This can be accomplished by instantiating a logger in each class, with the logger name equal to the fully qualified name of the class. This is a useful and straightforward method of defining loggers. As the log output bears the name of the generating logger, this naming strategy makes it easy to identify the origin of a log message. However, this is only one possible, albeit common, strategy for naming loggers. Logback does not restrict the possible set of loggers. As a developer, you are free to name loggers as you wish.
在Logback中,可以用 “组件” 来为logger命名。 在每个类中实例化logger,并将该类的完全限定名作为logger的name。 这种方式非常直接有效。 由于日志输出带有对应logger的名称,因此这种命名方式非常容易识别日志消息的来源。 当然,这只是一种可选的命名方式。 Logback不限制logger的名称。开发人员可根据需要命名logger。
Nevertheless, naming loggers after the class where they are located seems to be the best general strategy known so far.
尽管有种种因素, 但根据所在的class来命名logger一直是最佳实践。
The ability to selectively enable or disable logging requests based on their logger is only part of the picture. Logback allows logging requests to print to multiple destinations. In logback speak, an output destination is called an appender. Currently, appenders exist for the console, files, remote socket servers, to MySQL, PostgreSQL, Oracle and other databases, JMS, and remote UNIX Syslog daemons.
根据logger有选择地启用或禁用某些日志只是Logback的一个功能特征。 Logback可以将日志打印到多个地方。 在logback中,输出目标称为追加器(appender)。 目前,追加器支持 控制台(console),文件(file),远程套接字服务器,MySQL,PostgreSQL,Oracle以及其他数据库,JMS, 远程UNIX Syslog守护程序等等。
More than one appender can be attached to a logger.
同一个logger可以附加多个 Appender。
The addAppender method adds an appender to a given logger. Each enabled logging request for a given logger will be forwarded to all the appenders in that logger as well as the appenders higher in the hierarchy. In other words, appenders are inherited additively from the logger hierarchy. For example, if a console appender is added to the root logger, then all enabled logging requests will at least print on the console. If in addition a file appender is added to a logger, say L, then enabled logging requests for L and L's children will print on a file and on the console. It is possible to override this default behavior so that appender accumulation is no longer additive by setting the additivity flag of a logger to false.
addAppender方法用于将appender挂载到给定的logger下。 每次日志请求调用都会被转发给挂载到对应Logger的所有Appender, 以及更上层挂载的Appender。换句话说,追加器是从logger层次结构中继承而来的。
例如,如果将 console appender 挂载到 root logger,则启用的所有日志请求都会在控制台上打印。
如果某个 logger 还挂载了 file appender,例如 L ,则对 L 和 L 的下级logger来说, 启用的日志请求都会打印到控制台上和对应的文件中。
可以将logger的 additivity 标志设置为false,覆盖此默认行为,即不在多个appender中重复。
The rules governing appender additivity are summarized below.
下面是控制appender的additivity规则。
Appender Additivity
The output of a log statement of logger
Lwill go to all the appenders inLand its ancestors. This is the meaning of the term "appender additivity".
However, if an ancestor of logger
L, say P, has the additivity flag set to false, thenL's output will be directed to all the appenders inLand its ancestors up to and including P but not the appenders in any of the ancestors of P.
Loggers have their additivity flag set to true by default.
Appender的累加标志(Additivity)
记录器
L的日志语句, 会输出到L及其祖先挂载的所有 Appender。 这就是术语 "appender additivity" 的含义。
但是,如果记录器
L的祖先(例如P)的additivity标志设置为false,则L的输出只会传递给L直接绑定的追加器, 一直上溯至P[包含],但不会继续上溯至P的祖先绑定的追加器。
Logger的additivity标志默认为true。
The table below shows an example:
示例如下:
| Logger Name | Attached Appenders | Additivity Flag | Output Targets | Comment |
|---|---|---|---|---|
| root | A1 | not applicable | A1 | Since the root logger stands at the top of the logger hierarchy, the additivity flag does not apply to it. |
| x | A-x1, A-x2 | true | A1, A-x1, A-x2 | Appenders of "x" and of root. |
| x.y | true | A1, A-x1, A-x2 | Appenders of "x" and of root. | |
| x.y.z | A-xyz1 | true | A1, A-x1, A-x2, A-xyz1 | Appenders of "x.y.z", "x" and of root. |
| security | A-sec | false | A-sec | No appender accumulation since the additivity flag is set to false. Only appender A-sec will be used. |
| security.access | true | A-sec | Only appenders of "security" because the additivity flag in "security" is set to false. |
More often than not, users wish to customize not only the output destination but also the output format. This is accomplished by associating a layout with an appender. The layout is responsible for formatting the logging request according to the user's wishes, whereas an appender takes care of sending the formatted output to its destination. The PatternLayout, part of the standard logback distribution, lets the user specify the output format according to conversion patterns similar to the C language printf function.
我们不仅需要配置日志输出目标,还需要自定义日志的输出格式。 可以将appender与layout相关联来实现自定义输出格式。 layout 负责格式化日志,而 appender 负责将格式化后的输出内容发送到其目的地。 PatternLayout 是 Logback 标准发行版的一部分, 支持类似于C语言 printf 函数的模式定义输出格式。
For example, the PatternLayout with the conversion pattern "%-4relative [%thread] %-5level %logger{32} - %msg%n" will output something akin to:
PatternLayout的模板为 "%-4relative [%thread] %-5level %logger{32} - %msg%n", 输出的内容示例如下:
176 [main] DEBUG manual.architecture.HelloWorld2 - Hello world.
The first field is the number of milliseconds elapsed since the start of the program. The second field is the thread making the log request. The third field is the level of the log request. The fourth field is the name of the logger associated with the log request. The text after the '-' is the message of the request.
第一部分(%-4relative), 是自程序启动以来经过的毫秒数。
第二部分([%thread]) 是发出日志请求的线程名称。
第三部分(%-5level) 是日志请求的级别。
第四部分(%logger{32}) 是与日志请求相关的 logger 名称。
“-”之后的部分(%msg%n) 则是日志请求的文本消息。
Given that loggers in logback-classic implement the SLF4J's Logger interface, certain printing methods admit more than one parameter. These printing method variants are mainly intended to improve performance while minimizing the impact on the readability of the code.
logback-classic 实现了 SLF4J's Logger interface, 日志方法支持传入多个参数。
这些方法变体主要是为了提升性能,同时最大程度地减少对代码可读性的影响。
For some Logger logger, writing,
看看老式的日志调用:
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));
incurs the cost of constructing the message parameter, that is converting both integer i and entry[i] to a String, and concatenating intermediate strings. This is regardless of whether the message will be logged or not.
在构造 message 参数的时候,将 i 和 entry[i] 都转换为字符串,并进行拼接。 而系统配置却有可能将debug日志忽略。
One possible way to avoid the cost of parameter construction is by surrounding the log statement with a test. Here is an example.
假若日志消息体足够大,字符串拼接的成本可能受不了。 有一种优化方法是将log语句包含在if分支里。 示例如下。
if(logger.isDebugEnabled()) {
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));
}
This way you will not incur the cost of parameter construction if debugging is disabled for logger. On the other hand, if the logger is enabled for the DEBUG level, you will incur the cost of evaluating whether the logger is enabled or not, twice: once in debugEnabled and once in debug. In practice, this overhead is insignificant because evaluating a logger takes less than 1% of the time it takes to actually log a request.
如果禁用了debug日志,则不会产生参数构造的开销。
如果启用了DEBUG日志级别,则会产生两次计算的成本: 一次是 debugEnabled 方法, 一次是 debug 方法。 实际上,这点开销微不足道,因为计算logger是否开启DEBUG级别所花费的时间,还不到实际记录日志请求的1%。
There exists a convenient alternative based on message formats. Assuming entry is an object, you can write:
logback提供了一种基于消息格式化的替代方法,我们可以这样使用:
Object entry = new SomeObject();
logger.debug("The entry is {}.", entry);
Only after evaluating whether to log or not, and only if the decision is positive, will the logger implementation format the message and replace the '{}' pair with the string value of entry. In other words, this form does not incur the cost of parameter construction when the log statement is disabled.
logback会先计算是否要记录此日志, 只在发现确实需要记录的情况下, logger实现才会格式化消息,并将 '{}' 对替换为 entry 的字符串值。
换句话说,禁用log之后,这种方式不再有构造日志参数的开销。
The following two lines will yield the exact same output. However, in case of a disabled logging statement, the second variant will outperform the first variant by a factor of at least 30.
下面两行代码的输出完全相同。 但如果 log 请求被禁用, 第二种方式的性能将比第一种要高出30倍以上。
logger.debug("The new entry is "+entry+".");
logger.debug("The new entry is {}.", entry);
A two argument variant is also available. For example, you can write:
两个参数占位符的方式:
logger.debug("The new entry is {}. It replaces {}.", entry, oldEntry);
If three or more arguments need to be passed, an Object[] variant is also available. For example, you can write:
如果格式化参数超过3个,建议使用 Object[] 的方式:
Object[] paramArray = {newVal, below, above};
logger.debug("Value {} was inserted between {} and {}.", paramArray);
After we have introduced the essential logback components, we are now ready to describe the steps that the logback framework takes when the user invokes a logger's printing method. Let us now analyze the steps logback takes when the user invokes the info() method of a logger named com.wombat.
介绍了基本的logback组件之后, 调用logger的打印方法时, logback框架所执行的步骤可以试着理解了。
下面我们一起来分析当用户调用 (名为 com.wombat) logger 的 info()方法时,logback 的执行步骤。
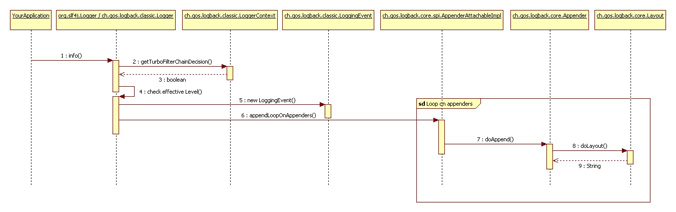
If it exists, the TurboFilter chain is invoked. Turbo filters can set a context-wide threshold, or filter out certain events based on information such as Marker, Level, Logger, message, or the Throwable that are associated with each logging request. If the reply of the filter chain is FilterReply.DENY, then the logging request is dropped. If it is FilterReply.NEUTRAL, then we continue with the next step, i.e. step 2. In case the reply is FilterReply.ACCEPT, we skip the next and directly jump to step 3.
如果存在 TurboFilter 则调用。 Turbo 过滤器会设置上下文范围的阈值, 根据日志请求相关联的信息(如 Marker, Level, Logger, message, 以及Throwable)来过滤掉某些事件。
如果过滤器链返回的是 FilterReply.DENY, 就会清掉这次日志请求。 如果返回的是 FilterReply.NEUTRAL,那么执行步骤2。
如果返回的是 FilterReply.ACCEPT,则忽略步骤2,直接跳至步骤3。
At this step, logback compares the effective level of the logger with the level of the request. If the logging request is disabled according to this test, then logback will drop the request without further processing. Otherwise, it proceeds to the next step.
步骤2中,logback 比较 logger 的有效级别与本次日志请求的级别。 如果判定本次日志请求被禁用,则logback会丢弃该请求,无需进一步处理。 否则,继续执行下一步。
LoggingEvent objectLoggingEvent 对象If the request survived the previous filters, logback will create a ch.qos.logback.classic.LoggingEvent object containing all the relevant parameters of the request, such as the logger of the request, the request level, the message itself, the exception that might have been passed along with the request, the current time, the current thread, various data about the class that issued the logging request and the MDC. Note that some of these fields are initialized lazily, that is only when they are actually needed. The MDC is used to decorate the logging request with additional contextual information. MDC is discussed in a subsequent chapter.
如果经过前面的过滤器之后请求仍然存在,则logback会创建 ch.qos.logback.classic.LoggingEvent 对象,其中包含请求相关的所有参数,例如请求的logger,请求对应的level,以及消息体, 以及随请求一起传递进来的 exception 对象,当前时间,当前线程,发出日志请求的class相关数据, 以及 MDC。 请注意,其中某些字段是懒加载的。 MDC 通过其他上下文信息来修饰日志请求。 详细的 MDC 信息请参考: subsequent chapter.
After the creation of a LoggingEvent object, logback will invoke the doAppend() methods of all the applicable appenders, that is, the appenders inherited from the logger context.
创建LoggingEvent对象后,logback将对所有匹配到的 appender 调用 doAppend()方法,即从 logger context 继承的附加器。
All appenders shipped with the logback distribution extend the AppenderBase abstract class that implements the doAppend method in a synchronized block ensuring thread-safety. The doAppend() method of AppenderBase also invokes custom filters attached to the appender, if any such filters exist. Custom filters, which can be dynamically attached to any appender, are presented in a separate chapter.
logback自带的所有附加器都继承自 AppenderBase 抽象类, 为了确保线程安全,其中的doAppend方法使用了同步块(synchronized)。
AppenderBase的 doAppend()方法也会调用挂载到appender上的自定义过滤器。
动态挂载到appender上的自定义过滤器请参考: filters.。
It is responsibility of the invoked appender to format the logging event. However, some (but not all) appenders delegate the task of formatting the logging event to a layout. A layout formats the LoggingEvent instance and returns the result as a String. Note that some appenders, such as the SocketAppender, do not transform the logging event into a string but serialize it instead. Consequently, they do not have nor require a layout.
附加器负责格式化自己的日志。 但也有一部分附加器将格式化日志的操作委托给了 layout。 layout 格式化 LoggingEvent 对象并返回 String 格式的结果。 请注意,某些附加器(例如SocketAppender)不会将日志事件转换为string,而是将其序列化, 也就不需要 layout。
LoggingEvent
LoggingEvent
After the logging event is fully formatted it is sent to its destination by each appender.
日志事件完成格式化后,appender需要将其发送到自己的目标位置。
Here is a sequence UML diagram to show how everything works. You might want to click on the image to display its bigger version.
下面的UML顺序图展示了工作原理。
One of the often-cited arguments against logging is its computational cost. This is a legitimate concern as even moderately-sized applications can generate thousands of log requests. Much of our development effort is spent measuring and tweaking logback's performance. Independently of these efforts, the user should still be aware of the following performance issues.
反对记日志的一个理由是计算成本。 这是一个合理的问题,即使是常规的应用系统也会产生成千上万的日志请求。 我们的很多开发工作都花在了衡量和调优logback的性能上。 即使工作内容与此无关,开发者仍然需要关心日志系统的性能问题。
You can turn off logging entirely by setting the level of the root logger to Level.OFF, the highest possible level. When logging is turned off entirely, the cost of a log request consists of a method invocation plus an integer comparison. On a 3.2Ghz Pentium D machine this cost is typically around 20 nanoseconds.
可以将 root logger 的级别设置为最高级别 Level.OFF, 来完全关闭日志记录。
完全关闭后,日志请求的成本包括方法调用和整数比较。 在 3.2Ghz 的 Pentium D机器上,此操作的时间成本为20纳秒左右。
However, any method invocation involves the "hidden" cost of parameter construction. For example, for some logger x writing,
但是,任何方法调用都涉及参数构造的“隐藏”成本。 例如,对 logger x 的写入,
x.debug("Entry number: " + i + "is " + entry[i]);
incurs the cost of constructing the message parameter, i.e. converting both integer i and entry[i] to a string, and concatenating intermediate strings, regardless of whether the message will be logged or not.
这里就有日志消息内容构造的成本,即将 i 和 entry[i] 都转换为字符串,并连接中间字符串,不管这个日志是否生效。
The cost of parameter construction can be quite high and depends on the size of the parameters involved. To avoid the cost of parameter construction you can take advantage of SLF4J's parameterized logging:
参数构造的开销可能很大,这取决于参数有多大。 为了避免不必要的参数构造开销,可以利用 SLF4J 的占位符与参数化方式记录日志:
x.debug("Entry number: {} is {}", i, entry[i]);
This variant will not incur the cost of parameter construction. Compared to the previous call to the debug() method, it will be faster by a wide margin. The message will be formatted only if the logging request is to be sent to attached appenders. Moreover, the component that formats messages is highly optimized.
这个重载方法没有拼接参数的成本。 与之前的 debug() 方法调用相比,它的速度将大大提高。 只有将日志请求发送到 appender 时,消息才会被格式化。 此外,格式化消息的组件一般是进行过深度优化的。
Notwithstanding the above placing log statements in tight loops, i.e. very frequently invoked code, is a lose-lose proposal, likely to result in degraded performance. Logging in tight loops will slow down your application even if logging is turned off, and if logging is turned on, will generate massive (and hence useless) output.
尽管将上面的日志语句放在大量的循环中是一种不好的习惯,即频繁地调用代码时,可能导致性能下降。 即使关闭日志记录,大量循环输出的日志也拖慢应用系统的速度; 如果开启日志功能,则会生成大量无用的输出。
In logback, there is no need to walk the logger hierarchy. A logger knows its effective level (that is, its level, once level inheritance has been taken into consideration) when it is created. Should the level of a parent logger be changed, then all child loggers are contacted to take notice of the change. Thus, before accepting or denying a request based on the effective level, the logger can make a quasi-instantaneous decision, without needing to consult its ancestors.
在logback中,无需遍历logger层次结构。 在创建logger时便明确知道其有效级别(即只会计算一次继承级别)。 如果更改了 parent logger 的级别, 则会通知所有子记录器进行更改。 因此,在基于有效级别判断接受或拒绝请求时, logger 可以即时做出决定,而无需遍历咨询其祖先。
This is the cost of formatting the log output and sending it to its target destination. Here again, a serious effort was made to make layouts (formatters) perform as quickly as possible. The same is true for appenders. The typical cost of actually logging is about 9 to 12 microseconds when logging to a file on the local machine. It goes up to several milliseconds when logging to a database on a remote server.
格式化日志输出并将其发送到输出目标的成本。 我们在这里也付出了巨大的努力,使 layout(formatter)的执行速度更快。 appender 也是如此。 输出到本地机器上的文件时,实际记录日志的成本约为9到12微秒(microsecond)。 如果输出到远程数据库服务器,需要几毫秒的时间。
Although feature-rich, one of the foremost design goals of logback was speed of execution, a requirement which is second only to reliability. Some logback components have been rewritten several times to improve performance.
尽管功能丰富,但logback的首要设计目标之一是执行速度(speed),这是仅次于可靠性的要求(reliability)。 某些 logback 组件已被多次重写以优化性能。
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。





