

代码拉取完成,页面将自动刷新
同步操作将从 柠檬夕桐/neural 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
[TOC]
<-. (`-')_ (`-') _ (`-') (`-') _
\( OO) ) ( OO).-/ .-> <-.(OO ) (OO ).-/ <-.
,--./ ,--/ (,------.,--.(,--. ,------,) / ,---. ,--. )
| \ | | | .---'| | |(`-')| /`. ' | \ /`.\ | (`-')
| . '| |)(| '--. | | |(OO )| |_.' | '-'|_.' | | |OO )
| |\ | | .--' | | | | \| . .'(| .-. |(| '__ |
| | \ | | `---.\ '-'(_ .'| |\ \ | | | | | |'
`--' `--' `------' `-----' `--' '--' `--' `--' `-----'
作者:echo(李景枫 or 李茹钰)
微服务架构中的神经组织,主要为分布式架构提供了集群容错的三大利刃:限流、降级和熔断。并同时提供了SPI、过滤器、JWT、重试机制、插件机制。此外还提供了很多小的黑科技(如:IP黑白名单、UUID加强版、Snowflake和大并发时间戳获取等)。
核心功能:
交流群
| QQ交流群:191958521(微服务基础设施) | 微信交流群:echo-lry(备注拉群要求) | 微信公众号:微技术栈 |
 |
 |
 |
Limiter)
Degrade)
Retryer)
Auth)
Trace)
Perf:性能测试神器,可以用于为单个方法或代码块进行性能测试NUUID:UUID扩展版,提供更丰富的UUID生产规则Filter:基于责任链模式的过滤器IPFilter:IP黑白名单过滤器Snowflake:基于Snowflake算法的分布式ID生成器SystemClock:解决大并发场景下获取时间戳时的性能问题TODO:需要实现对扩展点IoC和AOP的支持,一个扩展点可以直接setter注入其它扩展点。
第一步:定义接口
@SPI
public interface IDemo {}
第二步:定义接口实现类
@Extension("demo1")
public class Demo1Impl implements IDemo {}
@Extension("demo2")
public class Demo2Impl implements IDemo {}
第三步:使用接口全路径(包名+类名)创建接口资源文件
src/main/resources/META-INF/neural/io.neural.demo.IDemo
第四步:在接口资源文件中写入实现类全路径(包名+类名)
io.neural.demo.Demo1Impl
io.neural.demo.Demo2Impl
第五步:使用ExtensionLoader来获取接口实现类
public class Demo{
public static void main(String[] args){
IDemo demo1 =ExtensionLoader.getLoader(IDemo.class).getExtension("demo1");
IDemo demo2 =ExtensionLoader.getLoader(IDemo.class).getExtension("demo2");
}
}
在分布式架构中,限流的场景主要分为两种:injvm模式和cluster模式。

使用JDK中的信号量(Semaphore)进行控制。
public class Test{
public static void main(String[] args){
Semaphore semaphore = new Semaphore(10,true);
semaphore.acquire();
//do something here
semaphore.release();
}
}
使用Google的Guava中的限速器(RateLimiter)进行控制。
public class Test{
public static void main(String[] args){
RateLimiter limiter = RateLimiter.create(10.0); // 每秒不超过10个任务被提交
limiter.acquire(); // 请求RateLimiter
}
}
分布式限流主要适用于保护集群的安全或者用于严格控制用户的请求量(API经济)。
https://www.jianshu.com/p/a3d068f2586d
算法描述
属性
优点:流量比较平滑,并且可以抵挡一定的流量突发情况
在分布式架构中,熔断的场景主要分为两种:injvm模式和cluster模式。
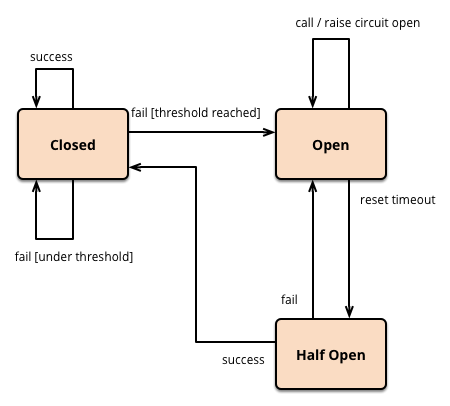
在指定时间周期内根据事件发生的次数来实现精简版熔断器。如10秒之内触发5次事件,则进行熔断。
TODO
服务降级是指当服务器压力剧增时,根据当前业务情况及流量对一些服务和页面有策略的降级,以此缓解了服务器资源压力,以保证核心任务的正常运行,同时也保证了部分甚至大部分客户得到正确响应。
当服务器检测到压力增大,服务器监测自动发送通知给运维人员,运维人员根据自己或相关人员判断后通过配置平台设置当前运行等级来降级。降级首先可以对非核心业务进行接口降级。如果效果不显著,开始对一些页面进行降级,以此保证核心功能的正常运行。
业务确定好对应业务的优先级别,指定好分级降级方案。当服务器检测到压力增大,服务检测自动发送通知给运维人员。运维人员根据情况选择运行等级。
使当前线程使用Thread.sleep()的方式进行休眠重试。
retryIfResult(Predicate< V> resultPredicate):设置重试不满足条件的结果
eg:如果返回结果为空则重试:retryIfResult(Predicates.< Boolean>isNull())
withRetryListener(RetryListener listener):添加重试监听器
withAttemptTimeLimiter(AttemptTimeLimiter< V> attemptTimeLimiter):添加尝试时间限制器
功能来源于java-jwt项目,但有一定的调整,后续会继续简化。
基于@SPI扩展方式和责任链模式实现的过滤器机制。
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。





