

代码拉取完成,页面将自动刷新
Redis构建了自己的类型系统,主要包括
C语言不是面向对象语言,这里将redisObject称呼为对象是为了讲述方便,让里面的内容更容易被理解,redisObject其实是一个结构体。
Redis内部使用一个redisObject对象来表示所有的key和value,每次在Redis数据块中创建一个键值对时,一个是键对象,一个是值对象,而Redis中的每个对象都是由redisObject结构来表示。
在Redis中,键总是一个字符串对象,而值可以是字符串、列表、集合等对象,所以我们通常说键为字符串键,表示这个键对应的值为字符串对象,我们说一个键为集合键时,表示这个键对应的值为集合对象
redisobject最主要的信息:
redisobject源码
typedef struct redisObject{
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//指向底层数据结构的指针
void *ptr;
//引用计数
int refcount;
//记录最后一次被程序访问的时间
unsigned lru:22;
}robj
type代表一个value对象具体是何种数据类型
encoding属性和*prt指针
prt指针指向对象底层的数据结构,而数据结构由encoding属性来决定
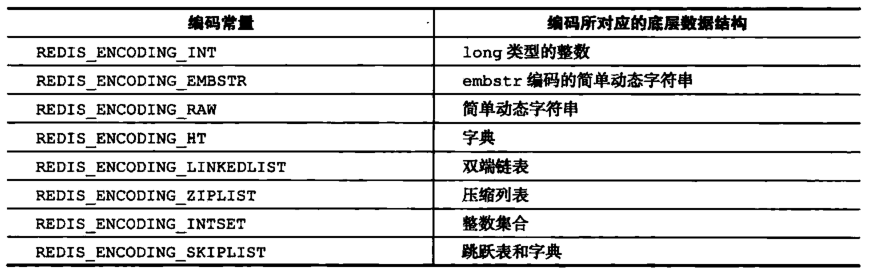
每种类型的对象至少使用了两种不同的编码,而这些编码对用户是完全透明的。
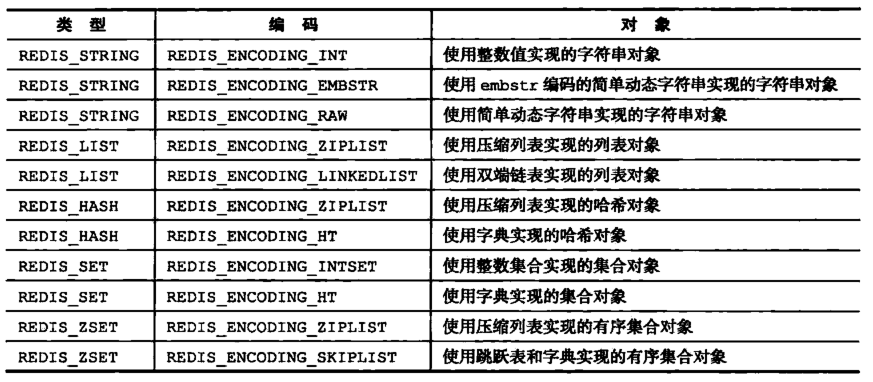
object encoding key命令可以查看值对象的编码
当执行一个处理数据类型的命令时,Redis执行以下步骤:
key ,在数据库字典中查找和它相对应的 redisObject ,如果没找到,就返回 NULL 。redisObject 的 type 属性和执行命令所需的类型是否相符,如果不相符,返回类型错误。redisObject 的 encoding 属性所指定的编码,选择合适的操作函数来处理底层的数据结构。string 是最常用的一种数据类型,普通的key/value存储都可以归结为string类型,value不仅是string,也可以是数字。其他几种数据类型的构成元素也都是字符串,注意Redis规定字符串的长度不能超过512M
int用来保存整数值,raw用来保存长字符串,embstr用来保存短字符串。embstr编码是用来专门保存短字符串的一种优化编码。
Redis中对于浮点型也是作为字符串保存的,在需要时再将其转换成浮点数类型
编码的转换
常用命令
set/get
mset /mget
127.0.0.1:6379> mset user1:name redis user1:age 22
OK
127.0.0.1:6379> mget user1:name user1:age
1) "redis"
2) "22"
incr && incrby<原子操作>
decr && decrby<原子操作>
setnx <小小体验一把分布式锁,真香>
setex
setrange/getrange
其他命令
应用场景
list列表,它是简单的字符串列表,你可以添加一个元素到列表的头部,或者尾部。
编码
常用命令
127.0.0.1:6379> lpush list1 hello
(integer) 1
127.0.0.1:637 9> lpush list1 world
(integer) 2
127.0.0.1:6379> lrange list1 0 -1
1) "world"
2) "hello"
127.0.0.1:6379> rpush list2 world
(integer) 1
127.0.0.1:6379> rpush list2 hello
(integer) 2
127.0.0.1:6379> lrange list2 0 -1
1) "world"
2) "hello"
127.0.0.1:6379> lrange list1 0 -1
1) "world"
2) "hello"
127.0.0.1:6379> lpop list1
"world"
127.0.0.1:6379> lrange list1 0 -1
1) "hello"
127.0.0.1:6379> lrange list2 0 -1
1) "hello"
2) "world"
127.0.0.1:6379> rpop list2
"world"
127.0.0.1:6379> lrange list2 0 -1
1) "hello"
127.0.0.1:6379> lpush list3 hello
(integer) 1
127.0.0.1:6379> lpush list3 world
(integer) 2
127.0.0.1:6379> linsert list3 before hello start
(integer) 3
127.0.0.1:6379> lrange list3 0 -1
1) "world"
2) "start"
3) "hello"
127.0.0.1:6379> lrange list1 0 -1
1) "a"
2) "b"
127.0.0.1:6379> lset list1 0 v
OK
127.0.0.1:6379> lrange list1 0 -1
1) "v"
2) "b"
127.0.0.1:6379> lrange list1 0 -1
1) "b"
2) "b"
3) "a"
4) "b"
127.0.0.1:6379> lrange list1 0 -1
1) "a"
2) "b"
实现数据结构
应用场景
集合对象set是string类型(整数也会转成string类型进行存储)的无序集合。注意集合和列表的区别:集合中的元素是无序的,因此不能通过索引来操作元素;集合中的元素不能有重复。
编码
集合对象的编码可以是intset或者hashtable
编码转换
常用命令
127.0.0.1:6379> sadd set1 aaa
(integer) 1
127.0.0.1:6379> sadd set1 bbb
(integer) 1
127.0.0.1:6379> sadd set1 ccc
(integer) 1
127.0.0.1:6379> smembers set1
1) "aaa"
2) "ccc"
3) "bbb"
srem: 删除集合元素
spop: 随机返回删除的key
sdiff :返回两个集合的不同元素 (哪个集合在前就以哪个集合为标准)
127.0.0.1:6379> smembers set1
1) "ccc"
2) "bbb"
127.0.0.1:6379> smembers set2
1) "fff"
2) "rrr"
3) "bbb"
127.0.0.1:6379> sdiff set1 set2
1) "ccc"
127.0.0.1:6379> sdiff set2 set1
1) "fff"
2) "rrr"
127.0.0.1:6379> sinterstore set3 set1 set2
(integer) 1
127.0.0.1:6379> smembers set3
1) "bbb"
sunion: 取两个集合的并集
sunionstore: 取两个集合的并集,并存入目标集合
smove: 将一个集合中的元素移动到另一个集合中
scard: 返回集合中的元素个数
sismember: 判断某元素是否存在某集合中,0代表否 1代表是
srandmember: 随机返回一个元素
127.0.0.1:6379> srandmember set1 1
1) "bbb"
127.0.0.1:6379> srandmember set1 2
1) "ccc"
2) "bbb"
应用场景
和集合对象相比,有序集合对象是有序的。与列表使用索引下表作为排序依据不同,有序集合为每一个元素设置一个分数(score)作为排序依据。
编码
有序集合的编码可以使ziplist或者skiplist
typedef struct zset{
//跳跃表
zskiplist *zsl;
//字典
dict *dice;
}zset
字典的键保存元素的值,字典的值保存元素的分值,跳跃表节点的object属性保存元素的成员,跳跃表节点的score属性保存元素的分值。这两种数据结构会通过指针来共享相同元素的成员和分值,所以不会产生重复成员和分值,造成内存的浪费。
编码转换
常用命令
127.0.0.1:6379> zrange zset 0 -1
1) "one"
2) "three"
3) "two"
4) "four"
5) "five"
6) "six"
127.0.0.1:6379> zcard zset
(integer) 6
127.0.0.1:6379> zcount zset 1 4
(integer) 4
127.0.0.1:6379> zrangebyscore zset 0 4 withscores
1) "one"
2) "1"
3) "three"
4) "2"
5) "two"
6) "2"
7) "four"
8) "4"
127.0.0.1:6379> zrange zset 0 -1
1) "one"
2) "three"
3) "two"
4) "four"
5) "five"
6) "six"
127.0.0.1:6379> zremrangebyrank zset 1 3
(integer) 3
127.0.0.1:6379> zrange zset 0 -1
1) "one"
2) "five"
3) "six"
127.0.0.1:6379> zrange zset 0 -1 withscores
1) "one"
2) "1"
3) "five"
4) "5"
5) "six"
6) "6"
127.0.0.1:6379> zremrangebyscore zset 3 6
(integer) 2
127.0.0.1:6379> zrange zset 0 -1 withscores
1) "one"
2) "1"
应用场景
hash对象的键是一个字符串类型,值是一个键值对集合
编码
hash对象的编码可以是ziplist或者hashtable
编码转换
hash是一个String类型的field和value之间的映射表
Hash特别适合存储对象
所存储的成员较少时数据存储为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht
Hash命令详解
hset/hget
127.0.0.1:6379> hset user id 1
(integer) 1
127.0.0.1:6379> hset user name z3
(integer) 1
127.0.0.1:6379> hset user add shanxi
(integer) 1
127.0.0.1:6379> hget user id
"1"
127.0.0.1:6379> hget user name
"z3"
127.0.0.1:6379> hget user add
"shanxi"
hmset/hmget
127.0.0.1:6379> hmset user id 1 name z3 add shanxi
OK
127.0.0.1:6379> hmget user id name add
1) "1"
2) "z3"
3) "shanxi"
hsetnx/hgetnx
hincrby/hdecrby
127.0.0.1:6379> hincrby user2 id 3
(integer) 6
127.0.0.1:6379> hget user2 id
"6"
127.0.0.1:6379> hget user2 id
"6"
127.0.0.1:6379> hmset user3 id 3 name w5
OK
127.0.0.1:6379> hlen user3
(integer) 2
127.0.0.1:6379> hgetall user3
1) "id"
2) "3"
3) "name"
4) "w3"
5) "add"
6) "beijing"
优点
缺点
应用场景
typedef struct redisObject{
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//指向底层数据结构的指针
void *ptr;
//引用计数
int refcount;
//记录最后一次被程序访问的时间
unsigned lru:22;
}robj
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。







