

代码拉取完成,页面将自动刷新
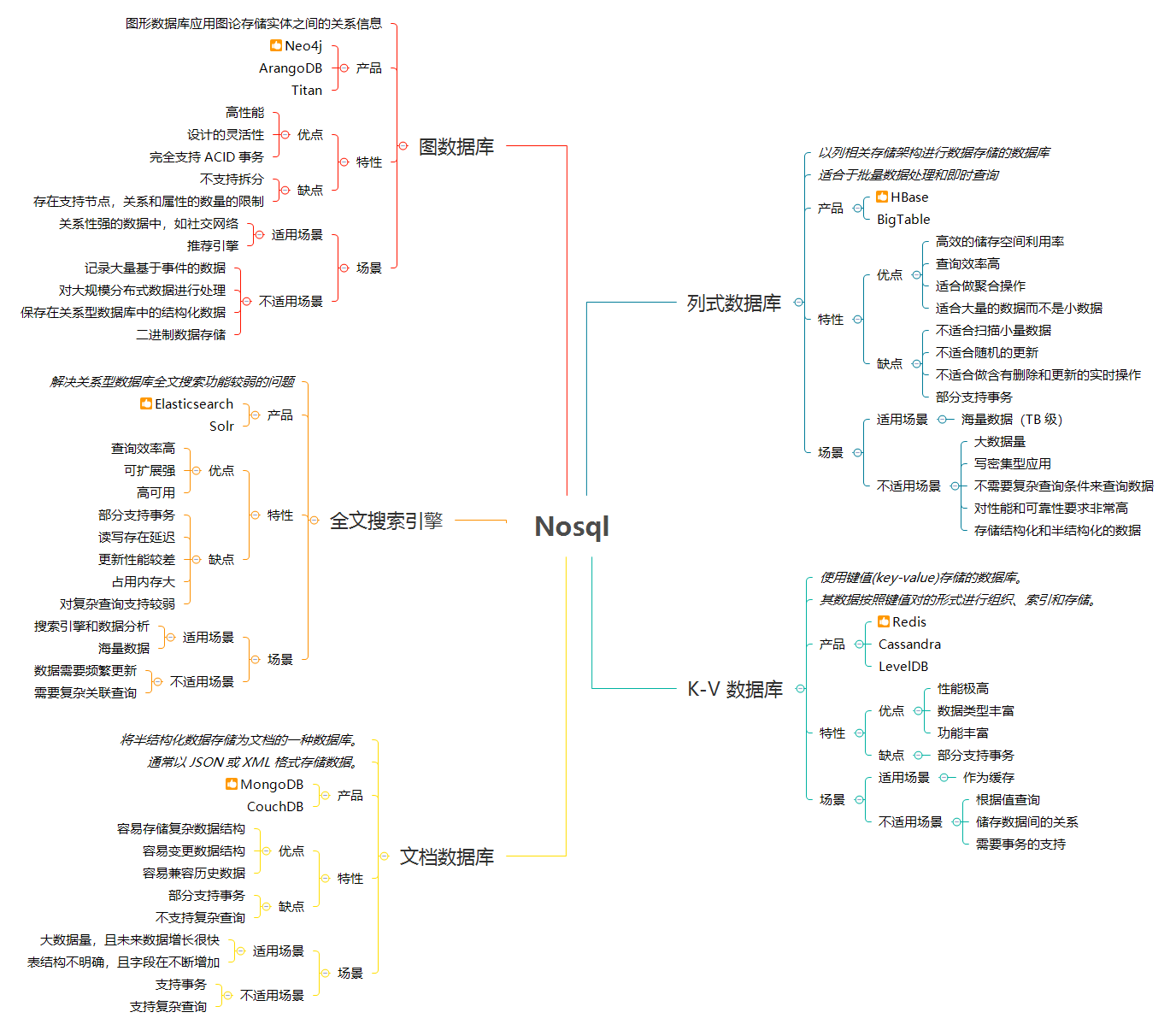
title: Nosql技术选型
date: 2020-02-09 02:18:58
categories:
- 数据库
- 数据库综合
tags:
- 数据库
- 综合
- Nosql
permalink: /pages/0e1012/
传统的关系型数据库存在以下缺点:
LIKE 查询的匹配会非常慢,即使在有索引的情况下。况且关系型数据库也不应该对文本字段进行索引。随着大数据时代的到来,越来越多的网站、应用系统需要支撑海量数据存储,高并发请求、高可用、高可扩展性等特性要求。传统的关系型数据库在应付这些调整已经显得力不从心,暴露了许多能以克服的问题。由此,各种各样的 NoSQL(Not Only SQL)数据库作为传统关系型数据的一个有力补充得到迅猛发展。

NoSQL,泛指非关系型的数据库,可以理解为 SQL 的一个有力补充。
在 NoSQL 许多方面性能大大优于非关系型数据库的同时,往往也伴随一些特性的缺失,比较常见的,是事务库事务功能的缺失。 数据库事务正确执行的四个基本要素:ACID 如下:
| 名称 | 描述 | |
|---|---|---|
| A | Atomicity (原子性) | 一个事务中的所有操作,要么全部完成,要么全部不完成,不会在中间某个环节结束。 事务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事务从来没有执行过一样。 |
| C | Consistency 一致性 | 在事务开始之前和事务结束以后,数据的数据的一致性约束没有被破坏。 |
| I | Isolation 隔离性 | 数据库允许多个并发事务同时对数据进行读写和修改的能力。隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。 |
| D | Durability 持久性 | 事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。 |
下面介绍 5 大类 NoSQL 数据针对传统关系型数据库的缺点提供的解决方案:
列式数据库是以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理和即时查询。
相对应的是行式数据库,数据以行相关的存储体系架构进行空间分配,主要适合于小批量的数据处理,常用于联机事务型数据处理。
基于列式数据库的列列存储特性,可以解决某些特定场景下关系型数据库 I/O 较高的问题。
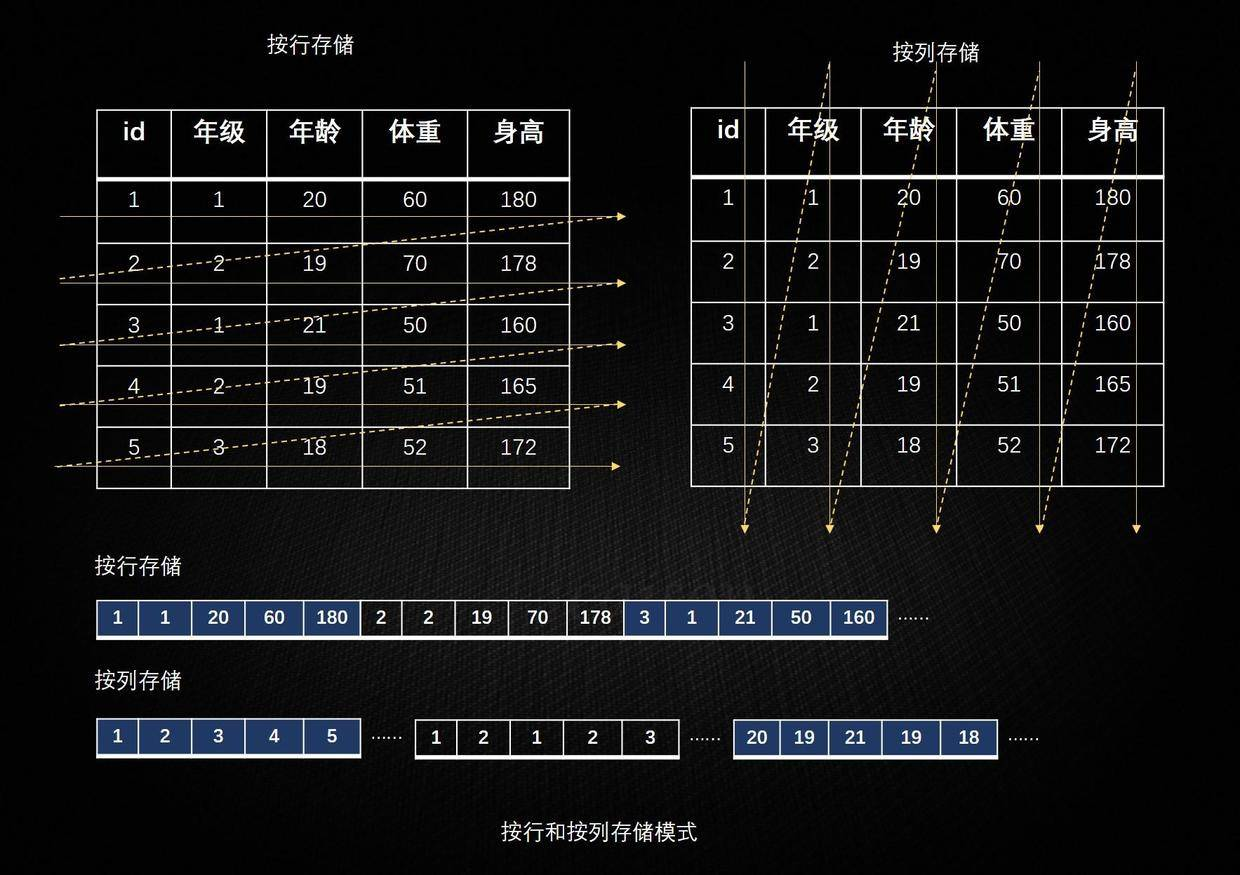
传统关系型数据库是按照行来存储数据库,称为“行式数据库”,而列式数据库是按照列来存储数据。
将表放入存储系统中有两种方法,而我们绝大部分是采用行存储的。 行存储法是将各行放入连续的物理位置,这很像传统的记录和文件系统。 列存储法是将数据按照列存储到数据库中,与行存储类似,下图是两种存储方法的图形化解释:
HBase
HBase 是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的 BigTable 建模,实现的编程语言为 Java。它是 Apache 软件基金会的 Hadoop 项目的一部分,运行于 HDFS 文件系统之上,为 Hadoop 提供类似于 BigTable 规模的服务。因此,它可以容错地存储海量稀疏的数据。
BigTable
BigTable 是一种压缩的、高性能的、高可扩展性的,基于 Google 文件系统(Google File System,GFS)的数据存储系统,用于存储大规模结构化数据,适用于云端计算。
优点如下:
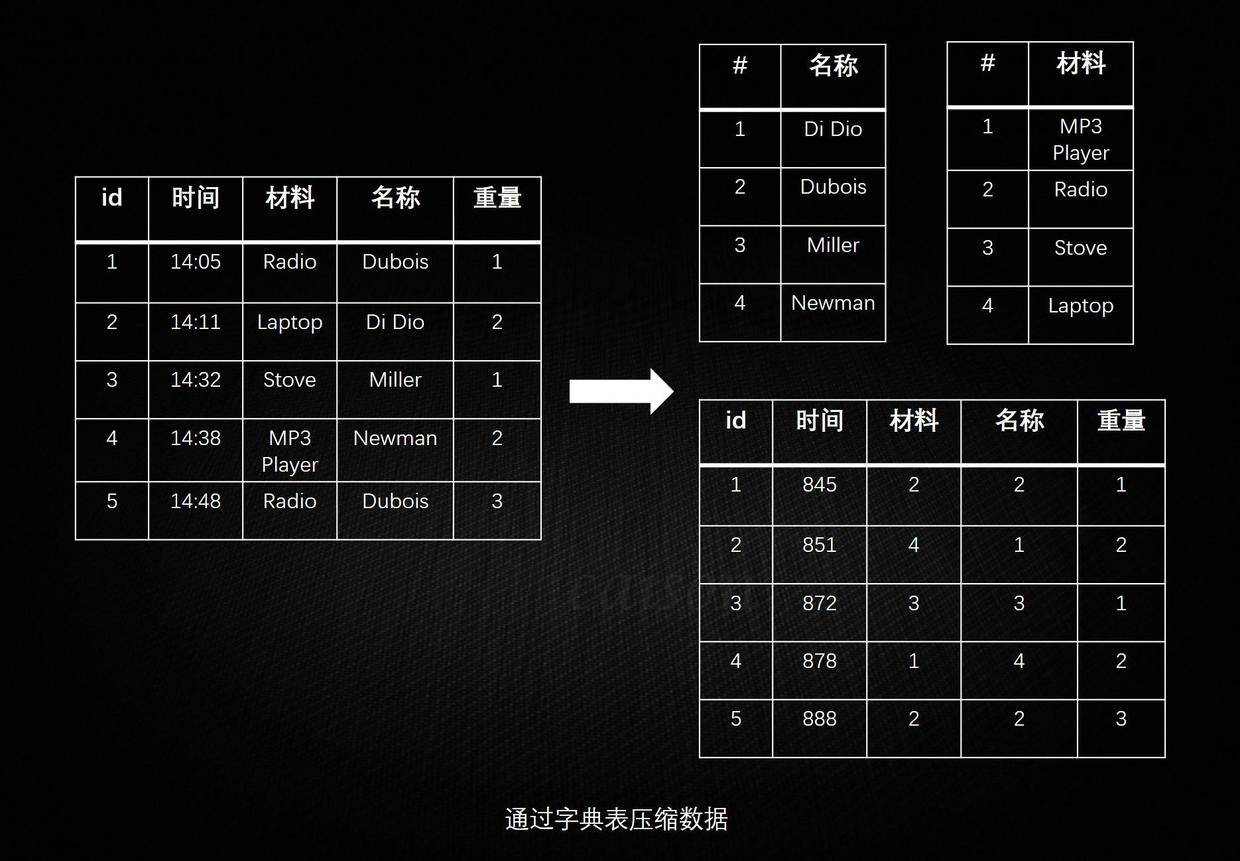
列式数据库由于其针对不同列的数据特征而发明的不同算法,使其往往有比行式数据库高的多的压缩率,普通的行式数据库一般压缩率在 3:1 到 5:1 左右,而列式数据库的压缩率一般在 8:1 到 30:1 左右。 比较常见的,通过字典表压缩数据: 下面中才是那张表本来的样子。经过字典表进行数据压缩后,表中的字符串才都变成数字了。正因为每个字符串在字典表里只出现一次了,所以达到了压缩的目的(有点像规范化和非规范化 Normalize 和 Denomalize)
读取多条数据的同一列效率高,因为这些列都是存储在一起的,一次磁盘操作可以数据的指定列全部读取到内存中。 下图通过一条查询的执行过程说明列式存储(以及数据压缩)的优点
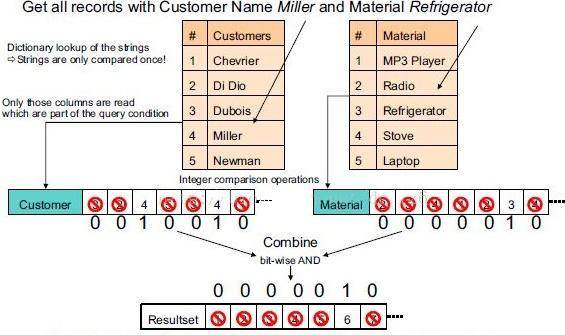
执行步骤如下:
i. 去字典表里找到字符串对应数字(只进行一次字符串比较)。
ii. 用数字去列表里匹配,匹配上的位置设为1。
iii. 把不同列的匹配结果进行位运算得到符合所有条件的记录下标。
iv. 使用这个下标组装出最终的结果集。
复制代码
缺点如下:
以 HBase 为例说明:
K-V 数据库指的是使用键值(key-value)存储的数据库,其数据按照键值对的形式进行组织、索引和存储。
KV 存储非常适合存储不涉及过多数据关系业务关系的数据,同时能有效减少读写磁盘的次数,比 SQL 数据库存储拥有更好的读写性能,能够解决关系型数据库无法存储数据结构的问题。
Redis

Redis 是一个使用 ANSI C 编写的开源、支持网络、基于内存、可选持久性的键值对存储数据库。从 2015 年 6 月开始,Redis 的开发由 Redis Labs 赞助,而 2013 年 5 月至 2015 年 6 月期间,其开发由 Pivotal 赞助。在 2013 年 5 月之前,其开发由 VMware 赞助。根据月度排行网站 DB-Engines.com 的数据显示,Redis 是最流行的键值对存储数据库。
Cassandra

Apache Cassandra(社区内一般简称为 C*)是一套开源分布式 NoSQL 数据库系统。它最初由 Facebook 开发,用于储存收件箱等简单格式数据,集 Google BigTable 的数据模型与 Amazon Dynamo 的完全分布式架构于一身。Facebook 于 2008 将 Cassandra 开源,此后,由于 Cassandra 良好的可扩展性和性能,被 Apple, Comcast,Instagram, Spotify, eBay, Rackspace, Netflix 等知名网站所采用,成为了一种流行的分布式结构化数据存储方案。
LevelDB

LevelDB 是一个由 Google 公司所研发的键/值对(Key/Value Pair)嵌入式数据库管理系统编程库, 以开源的 BSD 许可证发布。
以 Redis 为例:
优点如下:
缺点如下: 针对 ACID,Redis 事务不能支持原子性和持久性(A 和 D),只支持隔离性和一致性(I 和 C) 特别说明一下,这里所说的无法保证原子性,是针对 Redis 的事务操作,因为事务是不支持回滚(roll back),而因为 Redis 的单线程模型,Redis 的普通操作是原子性的。
大部分业务不需要严格遵循 ACID 原则,例如游戏实时排行榜,粉丝关注等场景,即使部分数据持久化失败,其实业务影响也非常小。因此在设计方案时,需要根据业务特征和要求来做选择
适用场景 - 储存用户信息(比如会话)、配置文件、参数、购物车等等。这些信息一般都和 ID(键)挂钩。
不适用场景
文档数据库(也称为文档型数据库)是旨在将半结构化数据存储为文档的一种数据库,它可以解决关系型数据库表结构 schema 扩展不方便的问题。文档数据库通常以 JSON 或 XML 格式存储数据。
由于文档数据库的 no-schema 特性,可以存储和读取任意数据。由于使用的数据格式是 JSON 或者 XML,无需在使用前定义字段,读取一个 JSON 中不存在的字段也不会导致 SQL 那样的语法错误。
MongoDB

MongoDB是一种面向文档的数据库管理系统,由 C++ 撰写而成,以此来解决应用程序开发社区中的大量现实问题。2007 年 10 月,MongoDB 由 10gen 团队所发展。2009 年 2 月首度推出。
CouchDB

Apache CouchDB 是一个开源数据库,专注于易用性和成为"完全拥抱 web 的数据库"。它是一个使用 JSON 作为存储格式,JavaScript 作为查询语言,MapReduce 和 HTTP 作为 API 的 NoSQL 数据库。其中一个显著的功能就是多主复制。CouchDB 的第一个版本发布在 2005 年,在 2008 年成为了 Apache 的项目。
以 MongoDB 为例进行说明
优点如下:
缺点如下:
MongonDB 还是支持多文档事务的 Consistency(一致性)和 Durability(持久性)
虽然官方宣布 MongoDB 将在 4.0 版本中正式推出多文档 ACID 事务支持,最后落地情况还有待见证。
适用场景:
不适用场景:
传统关系型数据库主要通过索引来达到快速查询的目的,在全文搜索的业务下,索引也无能为力,主要体现在:
LIKE 查询,而 LIKE 查询是整表扫描,效率非常低而全文搜索引擎的出现,正是解决关系型数据库全文搜索功能较弱的问题。
全文搜索引擎的技术原理称为 倒排索引(inverted index),是一种索引方法,其基本原理是建立单词到文档的索引。与之相对是,是“正排索引”,其基本原理是建立文档到单词的索引。
现在有如下文档集合:

正排索引得到索引如下:
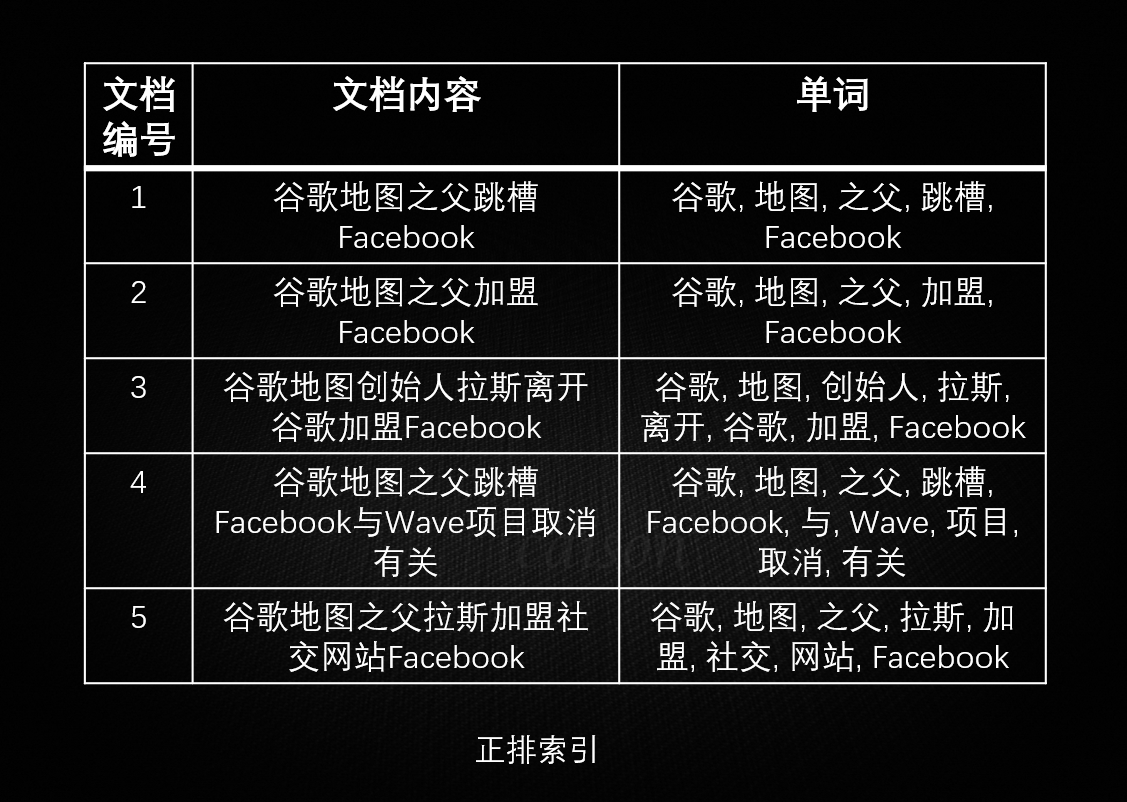
可见,正排索引适用于根据文档名称查询文档内容
简单的倒排索引如下:
带有单词频率信息的倒排索引如下:
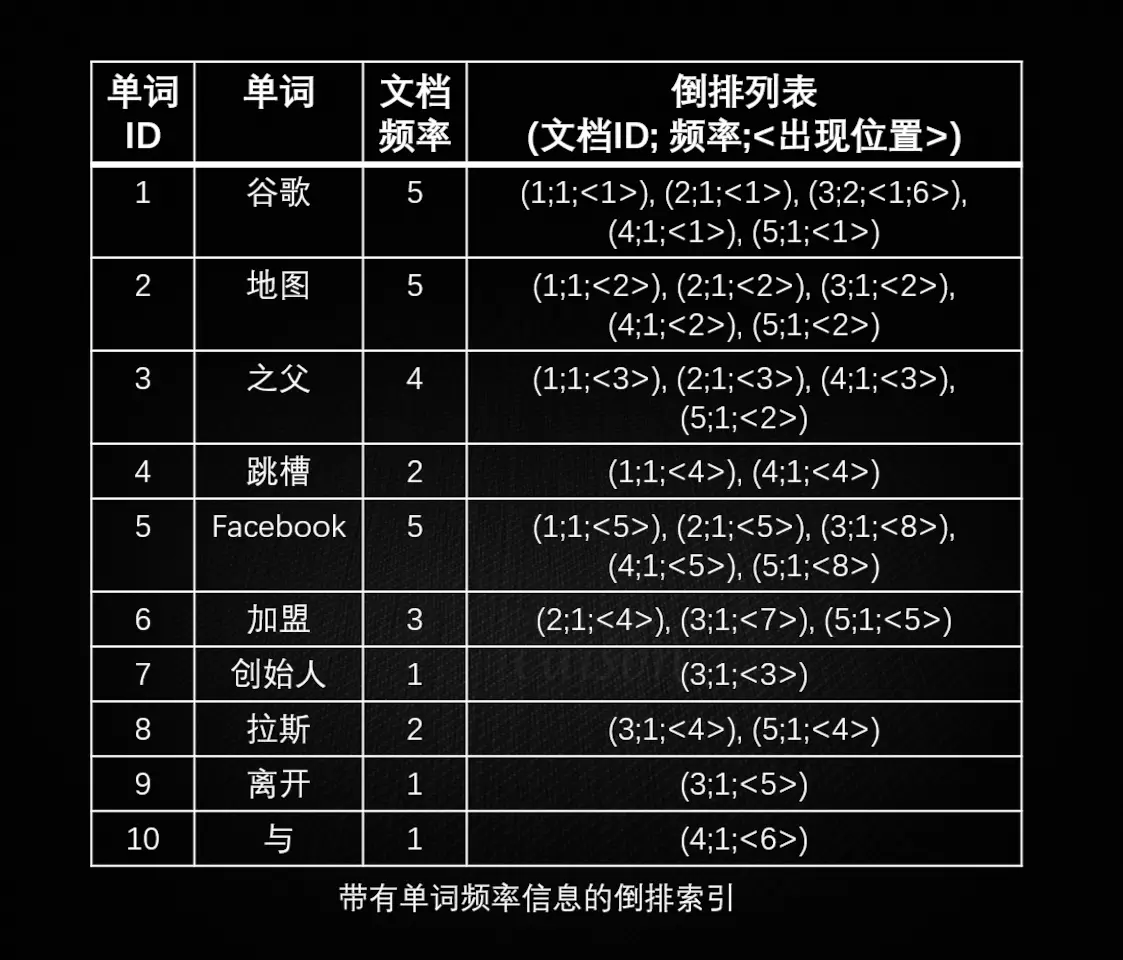
可见,倒排索引适用于根据关键词来查询文档内容
Elasticsearch
Elasticsearch 是一个基于 Lucene 的搜索引擎。它提供了一个分布式,多租户 -能够全文搜索与发动机 HTTP Web 界面和无架构 JSON 文件。Elasticsearch 是用 Java 开发的,并根据 Apache License 的条款作为开源发布。根据 DB-Engines 排名,Elasticsearch 是最受欢迎的企业搜索引擎,后面是基于 Lucene 的 Apache Solr。
Solr

Solr 是 Apache Lucene 项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如 Word、PDF)的处理。Solr 是高度可扩展的,并提供了分布式搜索和索引复制
以 Elasticsearch 为例: 优点如下:
缺点如下:
适用场景如下:
不适用场景如下:

图形数据库应用图论存储实体之间的关系信息。最常见例子就是社会网络中人与人之间的关系。关系型数据库用于存储“关系型”数据的效果并不好,其查询复杂、缓慢、超出预期,而图形数据库的独特设计恰恰弥补了这个缺陷,解决关系型数据库存储和处理复杂关系型数据功能较弱的问题。
Neo4j

Neo4j 是由 Neo4j,Inc。开发的图形数据库管理系统。由其开发人员描述为具有原生图存储和处理的符合 ACID 的事务数据库,根据 DB-Engines 排名, Neo4j 是最流行的图形数据库。
ArangoDB

ArangoDB 是由 triAGENS GmbH 开发的原生多模型数据库系统。数据库系统支持三个重要的数据模型(键/值,文档,图形),其中包含一个数据库核心和统一查询语言 AQL(ArangoDB 查询语言)。查询语言是声明性的,允许在单个查询中组合不同的数据访问模式。ArangoDB 是一个 NoSQL 数据库系统,但 AQL 在很多方面与 SQL 类似。
Titan

Titan 是一个可扩展的图形数据库,针对存储和查询包含分布在多机群集中的数百亿个顶点和边缘的图形进行了优化。Titan 是一个事务性数据库,可以支持数千个并发用户实时执行复杂的图形遍历。
以 Neo4j 为例:
Neo4j 使用数据结构中图(graph)的概念来进行建模。 Neo4j 中两个最基本的概念是节点和边。节点表示实体,边则表示实体之间的关系。节点和边都可以有自己的属性。不同实体通过各种不同的关系关联起来,形成复杂的对象图。
针对关系数据,2 种 2 数据库的存储结构不同:
Neo4j 中,存储节点时使用了”index-free adjacency”,即每个节点都有指向其邻居节点的指针,可以让我们在 O(1)的时间内找到邻居节点。另外,按照官方的说法,在 Neo4j 中边是最重要的,是”first-class entities”,所以单独存储,这有利于在图遍历的时候提高速度,也可以很方便地以任何方向进行遍历
如下优点:
缺点如下:
适用场景如下:
不适用场景如下:
关系型数据库和 NoSQL 数据库的选型,往往需要考虑几个指标:
常见软件系统数据库选型参考如下:
设计实践中,要基于需求、业务驱动架构,无论选用 RDB/NoSQL/DRDB,一定是以需求为导向,最终数据存储方案必然是各种权衡的综合性设计
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。






