

代码拉取完成,页面将自动刷新
mybatis-milu是基于mybatis的功能增强框架,遵循JPA规范的超轻量ORM拓展,提供通用Mapper接口,提供类似Spring Data JPA的查询创建器,通过方法名解析查询语句,极大提高开发效率。 本框架仅做功能增强,拓展statement的创建方式,不覆盖mybatis中的任何实现。
支持JPA的注解规范,但没有根据实体类注解声明生成表、索引等的功能,所以部分注解或注解属性用来生成表及索引的,使用后并无效果。
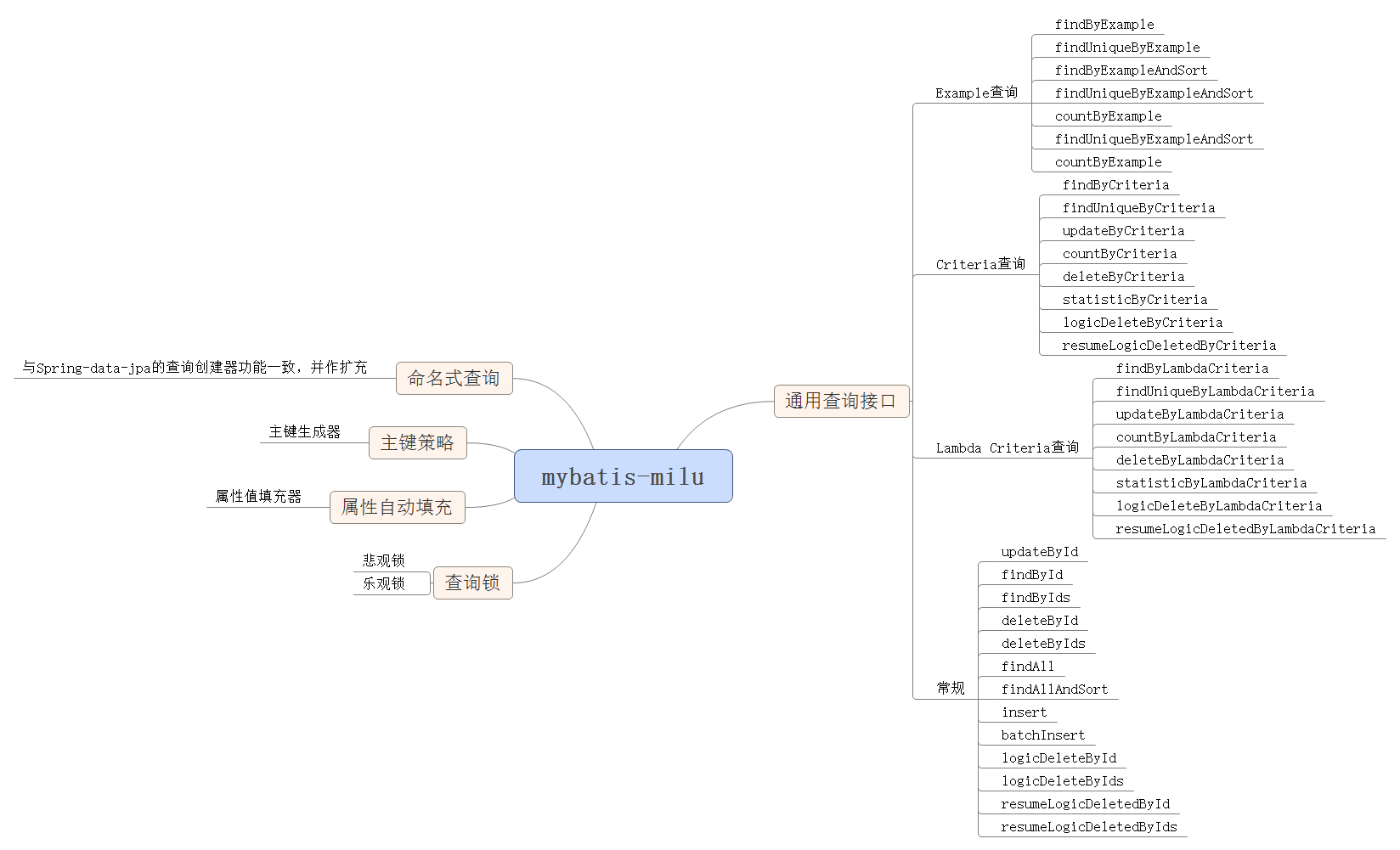
功能视图:
依赖
mybatis >= 3.5.0
pagehelper >=5.1.0
jdk >= 1.8
<!-- springboot2.x -->
<dependency>
<groupId>com.yuehuanghun</groupId>
<artifactId>mybatismilu-spring-boot-starter</artifactId>
<version>1.17.1</version> <!-- 获取最新版本 -->
</dependency>
<!-- springboot3.x -->
<dependency>
<groupId>com.yuehuanghun</groupId>
<artifactId>mybatismilu-spring-boot3-starter</artifactId>
<version>1.17.1</version> <!-- 获取最新版本 -->
</dependency>
基于知名的开源项目“若依管理系统”改版的项目:yadmin
如果你熟悉使用Hibernate等JPA框架,以下内容你会比较容易理解。
使用javax.persistence.Entity注解一个类为实体类。
可以使用javax.persistence.Table注解声明覆盖实体类的默认值。
可以使用javax.persistence.Column注解声明覆盖字段的默认值。
使用javax.persistence.Id注解声明这个属性为表的主键。
使用javax.persistence.Transient注解声明属性为非表字段或关联。
使用javax.persistence.OneToOne声明一对一的关系。
使用javax.persistence.ManyToOne声明多对一的关系。
使用javax.persistence.OneToMany声明一对多的关系
使用javax.persistence.ManyToMany声明多对多的关系
使用javax.persistence.JoinColumn声明实体(表)关联的信息
使用javax.persistence.JoinTable声明实体(表)关联的信息
@Data
@Entity
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.TABLE, generator = "tableSequence")
@TableGenerator(name = "tableSequence", table = "sequence", valueColumnName = "current_seq", pkColumnName = "id", pkColumnValue = "1")
private Long id; //使用数据表模拟数字序列
@AttributeOptions(filler = @Filler(fillOnInsert = true)) //当在插入数据时,如果该属性为null则自动填充值
private Date addTime;
@AttributeOptions(filler = @Filler(fillOnInsert = true, fillOnUpdate = true)) //当在插入或更新数据时,如果该属性为null则自动填充值
private Date updateTime;
@AttributeOptions(exampleQuery = @ExampleQuery(matchType = MatchType.CONTAIN)) //使用findByExample方法时name不为空时,即执行name LIKE %nameValue%
private String name;
private Integer age;
private Long classId;
@ManyToOne
@JoinColumn(name = "class_id", referencedColumnName = "id")
private Classs classs; //对多一引用
@OneToOne(mappedBy = "student")
private StudentProfile studentProfile; //一对一引用
}
@Entity
@Table(name = "class")
// @Table(name = "class", schema="指定schema") //指定schema可以访问非当前数据源默认库
@Data
public class Classs {
@Id
@GeneratedValue(strategy = GenerationType.AUTO, generator = Constants.ID_GENERATOR_SNOWFLAKE)
private Long id; //使用分布式ID,内置的snowflakeId
private Date addTime;
private String name;
@ManyToMany(mappedBy = "classList")
private List<Teacher> teacherList; //多对多关系演示,双向引用
@OneToMany(mappedBy = "classs")
private List<Student> studentList; //一对多关系演示,双向引用
}
一些注解声明可配置项比较多并复杂,会比较美感度。
从1.2.0版本开始,在用注解声明实体信息时,可以对@Id、@AttributeOptions自定义一个配置的别名注解,降低配置声明的繁杂度
内置对ID字段的注解别名:@SnowflakeId、@UUID
@Retention(RUNTIME)
@Target(FIELD)
public @interface SnowflakeId {
@Id
@GeneratedValue(generator = Constants.ID_GENERATOR_SNOWFLAKE)
String value() default StringUtils.EMPTY;
}
@Retention(RUNTIME)
@Target(FIELD)
public @interface UUID {
@Id
@GeneratedValue(generator = Constants.ID_GENERATOR_UUID)
String value() default StringUtils.EMPTY;
}
使得
public class SomeEntity {
@SnowflakeId
private Long id;
}
//等同于
public class SomeEntity {
@Id
@GeneratedValue(generator = Constants.ID_GENERATOR_SNOWFLAKE)
private Long id;
}
这样既简便又明了。
内置对通用字段的@AttributeOptions配置声明别名注解:@CrateTime、@UpdateTime
@Retention(RUNTIME)
@Target(FIELD)
public @interface CreateTime {
@AttributeOptions(filler = @Filler(fillOnInsert = true))
@Column(updatable = false)
String value() default StringUtils.EMPTY;
}
@Retention(RUNTIME)
@Target(FIELD)
@AttributeOptions(filler = @Filler(fillOnInsert = true, fillOnUpdate = true))
public @interface UpdateTime {
}
public class SomeEntity {
@CreateTime
private LocalDateTime CreateTime;
}
//等同于
public class SomeEntity {
@AttributeOptions(filler = @Filler(fillOnInsert = true)) //插入数据时自动添加当前日期,无需手动设值
@Column(updatable = false) //不可更新
private LocalDateTime CreateTime;
}
别名注解可以自定义,目前可以被配置的有@Id、@GeneratedValue、@AttributeOptions、@Column
自定义可以参考示范项目
JPA提供注解未能完全满足需要,因此也有一些此框架中自定义的注解
为了方便记忆,大部分拓展配置都可以通过以下三个注解进行声明,可以通过类的注释内容了解它们的功能
EnityOptions
实体选项
AttributeOptions
实体属性的选项
StatementOptions
Mapper查询方法的选项
Mapper接口通过继承BaseMapper接口类,获得通用的数据访问能力。 以下对一些特别的接口进行说明,简单的接口不再说明:
使用实体类对象作为查询条件。 默认情况下entity的属性值不为空时(not empty模式),将被作为查询条件,可以使用@AttributeOptions(conditionMode=Mode.xxx)更改条件的生效模式。 默认情况下属性作为查询条件时,使用值=匹配,可以@AttributeOptions(exampleQuery=@ExampleQuery(matchType=MatchType.xxx))更改查询匹配方式 同样适用
默认只查询主体的字段,如果你希望返回引用属性(关联表)的数据,可以在实体类上使用@FetchRef或@EntityOptions(fetchRefs={@FetchRef})进行声明
从1.12.0版本开始,example查询默认自动查询未删除数据的条件,并联表同理,如需关闭,需在实体类上添加@EntityOptions(filterLogicDeletedData = false)
通过@AttributeOptions(exampleQuery=@ExampleQuery(startKeyName="", endKeyName=""))指定传值的参数名
@AttributeOptions(exampleQuery=@ExampleQuery(startValueContain=true, endValueContain=true)) 可指定范围是开区间还是闭区间
@AttributeOptions(exampleQuery=@ExampleQuery(startKeyName="params.createTimeBegin", endKeyName="params.createTimeEnd"))
LocalDateTime createTime();
// SomeEntity example = new SomeEntity();
// example.getParams.put("createTimeBegin", LocalDateTime.now());
当范围是集合时,可使用@AttributeOptions(exampleQuery=@ExampleQuery(inKeyName=""))指定传值的参数名
值可为集合、数组或以半角逗号隔开多值的字符串。
@AttributeOptions(exampleQuery=@ExampleQuery(startKeyName="inKeyName="params.statusList"))
String status();
// SomeEntity example = new SomeEntity();
// example.getParams.put("statusList", "1,2,3");
// 或
// example.getParams.put("statusList", new String[]{"1","2","3"});
自定义条件查询,通过实体属性设置查询条件
//方式一
List<Classs> list = classMapper.findByCriteria(new QueryPredicateImpl().eq("name", "一年级").order(Direction.DESC,"id").order("studentListAddTime"));
//方式二
List<Classs> list = classMapper.findByCriteria(p -> p.eq("name", "一年级").order(Direction.DESC,"id").order("studentListAddTime"));
//查询多表
List<Classs> list = classMapper.findByCriteria(p -> p.select("*","studentList*").eq("id", 1L));
自定义条件查询,通过实体属性的lambda函数式设置查询条件
Classs params = new Classs();
params.setName("一年级");
//方式一
List<Classs> list = classMapper.findByLambdaCriteria(predicate -> predicate.apply(params).select(Classs::getName, Classs::getAddTime).eq(Classs::getName).limit(10, false));
//方式二
List<Classs> list = classMapper.findByLambdaCriteria(predicate -> predicate.select(Classs::getName, Classs::getAddTime).eq(Classs::getName, params.getName()).limit(10, false));
//查询多表
List<Classs> list = classMapper.findByLambdaCriteria(p -> p.select("*","studentList*").eq(Classs::getId, 1L));
目前支持5个统计关键字:sum/count/min/max/avg
List<Map<String, Object>> result = studentMapper.statisticByCriteria(p -> p.sum("age").avg("age").count("id").groupBy("classId").orderAsc("classId"));
// SELECT SUM(`age`) `ageSum`, AVG(`age`) `ageAvg`, COUNT(`id`) `idCount`, `class_id` classId FROM `student` GROUP BY `class_id` ORDER BY `class_id` ASC
统计字段别名为统计属性名+统计函数名,分组字段也会自动作为查询字段
可以指resultType
List<StudentStatistic> result = studentMapper.statisticByCriteria(p -> p.sum("age").avg("age").count("id").groupBy("classId").orderAsc("classId"), StudentStatistic.class);
最大值统计
maxByLambdaCriteria
Integer maxAge = studentMapper.maxByLambdaCriteria(Student::getAge, p ->{});
最小值统计
minByLambdaCriteria
Integer minAge = studentMapper.minByLambdaCriteria(Student::getAge, p ->{});
和统计
sumByLambdaCriteria
Integer totalAge = studentMapper.sumByLambdaCriteria(Student::getAge, p ->{});
classMapper.findByCriteria(p -> p.undeleted());
// 示意 -> SELECT * FROM classs WHERE is_deleted ='N';
classMapper.findByCriteria(p -> p.deleted());
// 示意 -> SELECT * FROM classs WHERE is_deleted ='Y';
在实际操作在,可以使用实体类来接收前端的参数,这时候使用Example查询非常方便:findByExample(Object example)
但由于Example查询功能有局限性,而Criteria查询比Example查询强,因然将example条件转为criteria条件,再补充设置就非常方便了。
User example = new User();
example.setUserName("zhangsan");
QueryPredicate predicate = Predicates.queryPredicate(Object example);
// 更多操作
userMapper.findByCriteria(predicate);
// 或
userMapper.findByCriteria(p -> {
p.byExample(example);
// 更多操作
})
与Spring Data JPA的查询创建器一致,并进行了拓展
@Mapper
public interface StudentMapper extends BaseMapper<Student, Long> {
@NamingQuery
public List<Student> findByName(String name);
@NamingQuery
public int countByName(String name);
@NamingQuery
public List<Student> findByClasssName(String className);
@NamingQuery
public List<Student> findTop5ByAddTimeAfter(Date addTimeBegin);
@NamingQuery
public List<Student> findByClasssNameOrderByClasssIdDescAddTimeAsc(String className);
}
在mapper中,使用@NamingQuery标识一个接口为查询创建器,否则会认为映射的的是由xml配置的statement
与spring data jpa一样,查询属性可以为关联实体的属性
@Mapper
public interface ClassMapper extends BaseMapper<Classs, Long> {
@NamingQuery
public List<Classs> findByTeacherListName(String teacherName);
@NamingQuery
public List<Classs> findByStudentListName(String studentName);
@NamingQuery
public List<Classs> findByStudentListNameInAndStudentListAgeGreaterThan(String[] studentNames, int age);
@NamingQuery
public List<Classs> findByAddTimeAfterAndAddTimeBefore(Date beginTime, Date endTime);
@NamingQuery
public List<Classs> findByAddTimeBetween(Date beginTime, Date endTime);
}
条件关键字
| 关键字 | 例子 | JPQL 片段 |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Between | findByStartDateBetween | … where x.startDate between 1? and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1(parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1(parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1(parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection age) | … where x.age not in ?1 |
| True | findByActiveTrue() | … where x.active = true |
| False | findByActiveFalse() | … where x.active = false |
操作关键字
| 关键字 | 例子 | JPQL 片段 |
|---|---|---|
| find/read/get/query/stream | findByLastname | select ... where x.lastname = ?1 |
| count | countByLastname | select count(*) from ... where x.lastname = ?1 |
| Distinct | findDistinctByLastname | select distinct ... where x.lastname = ?1 |
| delete/remove | deleteByLastname | delete from ... where x.lastname = ?1 |
| sum/count/min/max/avg | sumAgeAvgAgeCountIdByGroupByClassIdAndUpdateTime | SELECT SUM(age) ageSum, AVG(age) ageAvg, COUNT(id) idCount, class_id classId, update_time updateTime FROM student GROUP BY class_id, update_time |
返回行限制关键字(示例目标数据库为Mysql)
| 关键字 | 例子 | JPQL 片段 |
|---|---|---|
| Top | findTop5ByLastname | select ... where x.lastname = ?1 limit 5 |
| First | findFirstByLastname | select ... where x.lastname = ?1 limit 1 |
分页,直接在查询中添加Pageable参数即可,不需要在方法名上写表达式,并且参数位置任意。
@NamingQuery
public List<Student> findByNameLike(String name, Pageable page);
当page参数为null时,将不会分页
使用javax.persistence.GeneratedValue注解声明主键的创建方式
对于@GeneratedValue的strategy(策略)枚举,有不同的处理方式
| 策略 | 说明 |
|---|---|
| AUTO | 由generator指定一个生成器的名称 |
| IDENTITY | 由数据库自增或用户设值,等同于不声明@GeneratedValue |
| TABLE | 使用表模拟一个序列,需要同时配置@TableGenerator |
| SEQUENCE | 对于oracle这类支持序列的数据库,需要同时配置@SequenceGenerator |
AUTO的意义已经不是原JPA的定义,在本框架中的用途是设置一个自定义的ID生成器。
@Id
@GeneratedValue(strategy = GenerationType.AUTO, generator = Constants.ID_GENERATOR_SNOWFLAKE)
private Long id;
generator是com.yuehuanghun.mybatis.milu.id.IdentifierGenerator实现类的getName()获取的标识。
已内置两个分布式主键生成器:
com.yuehuanghun.mybatis.milu.id.impl.snowflake.SnowflakeIdentifierGenerator com.yuehuanghun.mybatis.milu.id.impl.UUIDIdentifierGenerator
对于标识为Constants.ID_GENERATOR_SNOWFLAKE和Constants.ID_GENERATOR_UUID常量
在springboot中,可以快速自定义一个主键生成器
@Component
public class MyIdentifierGenerator implements IdentifierGenerator {
@Override
public Serializable generate(IdGenerateContext context) {
return xxxx;
}
@Override
public String getName() {
return "myName";
}
}
使用数据表来模拟一个自增序列
@Id
@GeneratedValue(strategy = GenerationType.TABLE, generator = "tableSequence")
@TableGenerator(name = "tableSequence", table = "sequence", valueColumnName = "current_seq", pkColumnName = "id", pkColumnValue = "1")
private Long id;
对应表
CREATE TABLE `sequence` (
`id` INT(10) UNSIGNED NOT NULL COMMENT 'id',
`current_seq` BIGINT(20) UNSIGNED NOT NULL,
`seq_name` VARCHAR(50) NULL DEFAULT '',
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
)
适合ORCLE或类ORCEL数据库等可以配置自增序列的数据库
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "ignore")
@SequenceGenerator(sequenceName = "SEQ_STUDENT_ID", name = "ignore")
private Long id;
直接指定数据库中设定的序列表即可,@GeneratedValue中generator设置无意义
本框架使用PageHelper作为底层分页功能插件
除了使用pageHelper直接启动分页外,还有以下方式的分页开启方式:
以下SQL仅描述效果
1、使用有分页参数的通用方法
someMapper.findByExample(entityExmaple, new PageRequest(1, 10))
// SELECT ... LIMIT 10
2、当example是一个Pageable对象时,可直接设置分页,仅当getPageNum > 0 并且getPageSize() > 0时开启分页
public class User extends PageRequest {
}
User example = new User();
example.setPageNum(1);
example.setPageSize(10);
userMapper.findByExample(example);
// SELECT ... LIMIT 10
1、直接指定页码及页行数
someMapper.findByCriteria(p -> p.limit(2, 10))
// SELECT ... LIMIT 10, 10
2、使用Pageable对象传参
someMapper.findByCriteria(p -> p.limit(new PageRequest(2, 10)))
// SELECT ... LIMIT 10, 10
1、使用表达式,仅能查第一页的N条
public interface UserMapper extends BaseMapper<User, Long> {
@NamingQuery
List<User> findTop5ByUsernameLike(String username);
}
userMapper.findTop5ByUsernameLike("张%");
//SELECT .... WHERE username LIKE '张%' LIMIT 5
2、在查询参数中直接加入Pageable参数
public interface UserMapper extends BaseMapper<User, Long> {
List<User> findByUsernameLike(String username, Pageable page);
}
userMapper.findByUsernameLike("张%", new PageRequest(5));
//SELECT .... WHERE username LIKE '张%' LIMIT 5
另外,使用PageHelper排序时,可使用属性名,同时也建议使用属性名,框架最终会转为列名(注:在MapperXML中自定义的查询,无法转换)
PageHelper.startPage(1, 10, "addTime DESC");
//SELECT .... LIMIT 10 ORDER BY add_time DESC
仅可用于自动配置时,如果自定义配置则不生效
@EnableEntityGenericResultMap
public class App
{
public static void main( String[] args )
{
SpringApplication.run(App.class, args);
}
}
使用配置参数开启
property文件
mybatis.createEntityResultMap=true
yaml文件
mybatis.createEntityResultMap: true
启动类添加注解声明@EnableEntityGenericResultMap,在mapper.xml中可以直接使用resultMap
规则为对应Mapper.java的全路径 + 实体类名 + Map
例如:com.yuehuanghun.mybatismilu.test.domain.mapper.TeacherMapper.TeacherMap
在新增或更新实体时,有些字段希望能够自动填充的,常见的如创建日期、更新日期,可通过以下注解设置
@AttributeOptions(filler = @Filler(fillOnInsert = true, fillOnUpdate = true))
默认已经支持对以下类型进行自动填充
时间类,值为当前日期/日期时间:
数字类,值为0:
自定义填充:
@AttributeOptions(filler = @Filler(fillOnInsert = true, fillOnUpdate = true, attributeValueSupplier = ?))
通过设置attributeValueSupplier进行自定义数据提供者类,类实现AttributeValueSupplier即可。
你可以尝试在新增及更新时,自动设置创建人及更新人
分为乐观锁与悲观锁。
乐观锁假设数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,使用版本号字段匹配条件,如果更新失败则认为发生了冲突。
使用@Version注解声明一个实体类属性为版本字段,字段在数据库中必须为数字类型,因为版本需要自增。
在使用update更新时,如果Version属性不为null,则会自动作为查询条件;不管Version属性是否为空,框架都会在更新时将其自增。
注:在Hibernate框架中如果发生更新条数为0时,会抛出OptimisticLockException异常,在本框架中需要你自行判定。
悲观锁的实现需要数据库支持,一般分为悲观读锁与悲观写锁。
读锁,是指在本事务内,不会更新锁定的数据,但也不希望在本事务结束前,有别的事务更新这条(或这些)数据,多个事务可以同时获取读锁,事务如果要更新锁定的数据,则需要等到所有读锁释放。 写锁,是指在本事务内,将会更新锁定的数据,只有一个事务能获取指定数据的写锁。
@NamingQuery
@StatementOptions(asExpression = "findById", lockModeType = LockModeType.PESSIMISTIC_WRITE)
public Teacher findByIdWithLock(Long id);
@NamingQuery
@StatementOptions(asExpression = "findById", lockModeType = LockModeType.PESSIMISTIC_READ)
public Teacher findByIdWithShareLock(Long id);
在以上示例中,方法名显式地表达了这是一个需要获取锁的查询,但WithLock不是查询创建器中表达式,所以,为了查询创建器能够正确需要在@StatementOptions注解中属性asExpression重新定义表达式。
LockModeType是JPA规范中的枚举类型,枚举类型有很多,如果使用,有如下规则:
使用Criteria或LambdaCriteria查询时,如果在查询时上锁,只要调用lock方法即可。
List<Teacher> list = teacherMapper.findByCriteria(p -> p.eq("id", 1L).lock(LockModeType.PESSIMISTIC_WRITE)); //指定锁模式
List<Teacher> list = teacherMapper.findByCriteria(p -> p.eq("id", 1L).lock(); //默认悲观写锁
逻辑删除实际是针对特定属性进行更新
包含逻辑删除及恢复逻辑删除的接口,例如:
BaseMapper.logicDeleteById(ID id);
BaseMapper.resumeLogicDeleteById(ID id);
使用逻辑删除接口,必须先在实体类中声明逻辑删除属性
@LogicDelete
Object someAttr;
//或
@AttributeOptions(logicDelete = @LogicDelete)
Object someAttr;
@LogicDelete中,value是已删除状态的值,resumeValue是恢复到正常状态的值
value默认值为1、resumeValue默认值为0
更改默认值,例如:@LogicDelete(value = "Y", resumeValue = "N")
值会被转换为属性实际类型的对象
@LogicDelete的main属性值,当值为true时,在Criteria查询中的undeleted()、deleted()条件中作为查询条件
值中可以使用表达式,目前仅可用表达式为:#{now},表示当前时间,会根据实际属性类型取值
public class Example {
//支持多个逻辑删除属性
@LogicDelete(value = "Y", resumeValue = "N")
private Boolean isDeleted;
@LogicDelete(value = "#{now}", resumeValue = "") //删除时记录被删除的时间,恢复时更新为null
private LocalDateTime deleteTime;
}
@LogicDelete可通过provider指定的一个值的提供者,指定类为LogicDeleteProvider的实现类
如果想通过全局设置逻辑删除中,删除值与恢复值的的获取
自动化配置参数
mybatis:
configurationProperties:
logicDeleteProvider: #实现类的类路径
如果是手动配置可以设置MiluConfiguration.setDefaultLogicDeleteProvider
属性上的provider优先级高于全局provider,一旦设置了provider则@LogicDelete上的value与resumeValue值将无用
为了方便支持C(controller)-S(service)-D(dao)编程规范中使用查询,框架中特别提供了BaseService接口,以简化Serice层的编写。
代码示例:
@Entity
public class SomeEntity {
@Id
private Long id;
}
public interface ISomeEntitySerice extends BaseService<SomeEntity, Long, SomeEntityMapper> {
}
@Service
public class SomeEntitySericeImpl extends BaseServiceImpl<SomeEntity, Long, SomeEntityMapper> implements ISomeEntitySerice {
}
即可在Controller中使用BaseService定义的大量通用接口。
占位符的应用场景目前有
实现接口PlaceholderResolver并设置到MiluConfiguration对象中
在SpringBoot环境中,已实现了SpringPlaceholderResolver并自动配置,可以直接使用SpEL进行占位符定义。
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。






