

代码拉取完成,页面将自动刷新
scrapy是python爬虫生态中最流行的框架,架构清晰,拓展性强,通常我们使用requests或aiohttp实现整个爬虫逻辑,但整个过程中其实有很多步骤是重复的,即然如此,我们完全可以吧这些步骤的逻辑抽离出来,把通用的功能做成一个又一个的通用组件。
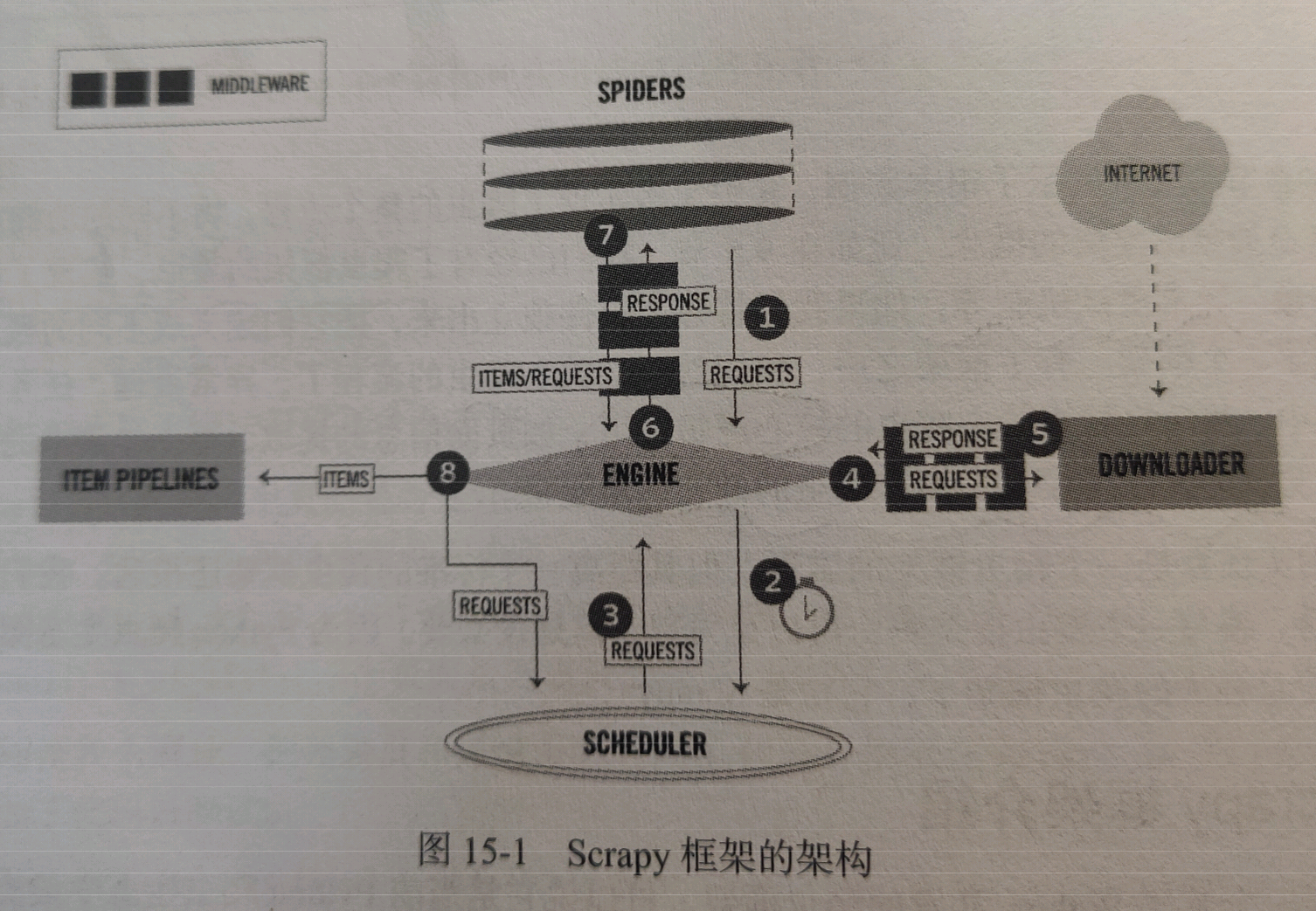
scrapy框架的架构,如图所示:
本次我们需要爬取的站点为:https://antispider7.scrape.center/ ,这个站点需要登录才能爬取,登录之后(帐号和密码均是admin),我们便可以看到如下画面:

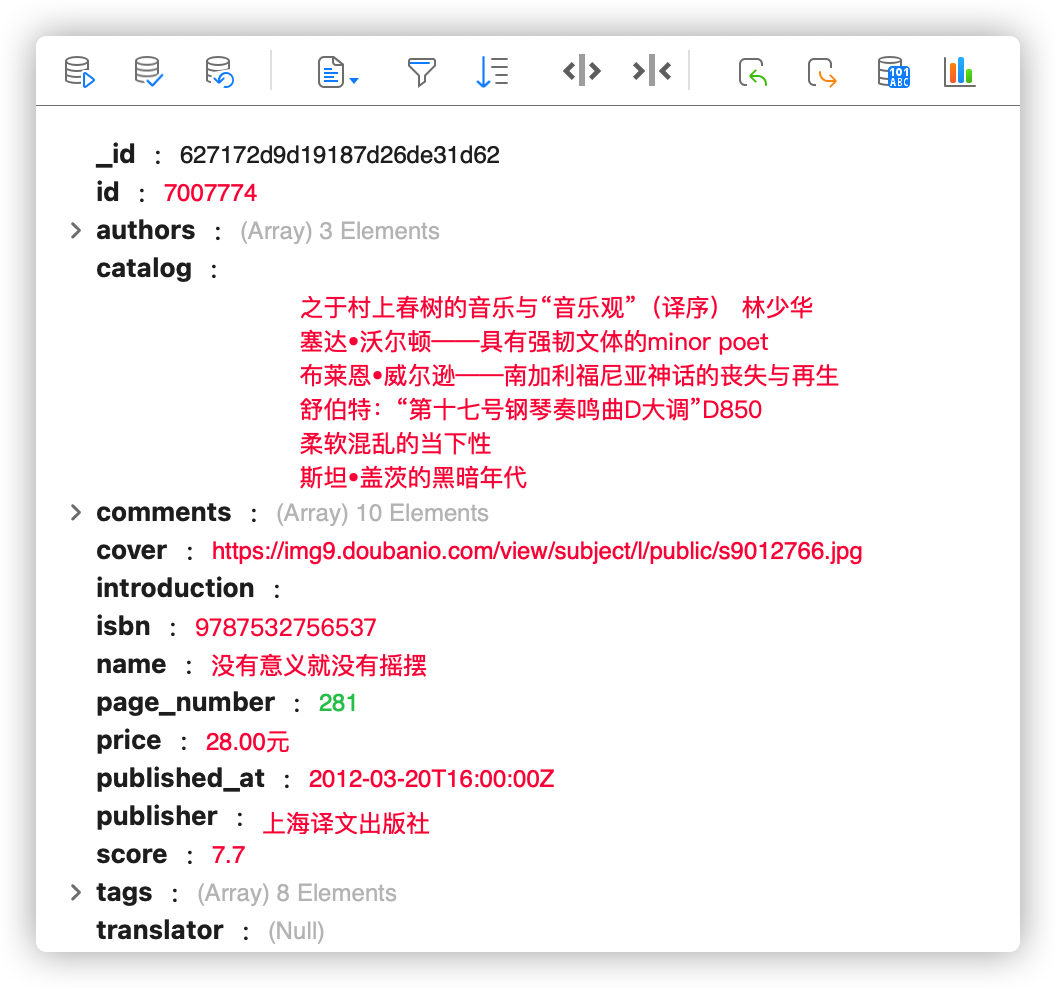
这里是一些书籍信息,我们需要进入每一本书对应的详情页,将改本书的信息爬取下来,总数接近1万本。需要将数据保存至本地mongodb数据库中。交付结果如下图:
这个站点设置了如下的一些反爬措施,但个账号每5分钟内最多访问页面10次,平均下载每分钟最多访问2次,超过则被封号;此外站点还设置了IP的封禁,同样每5分钟最多访问10次。
主要面临两个障碍:
用帐号登录后,列表页url分析: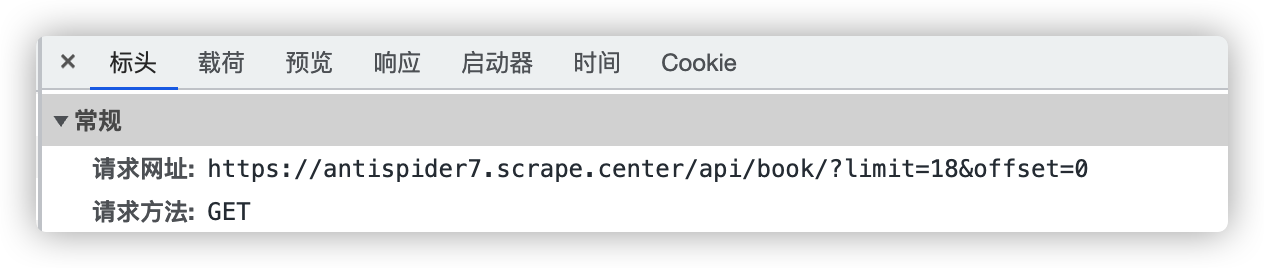
 ajax请求,url中无加密参数,接下来查看登录验证方式:
ajax请求,url中无加密参数,接下来查看登录验证方式:
属于JWT验证,接下来查看详情页url构造方式。
详情页url分析

 url中
url中7952978属于列表页中的ID。
爬取逻辑已清洗,先从列表页接口获取书籍ID,再根据ID构造详情页接口Url,爬取每一本书的详情;模拟登录是jwt方式,在请求体中加入authorization字段。
新建scrapy项目
scrapy startproject scrapycompositedemo
进入项目,新建一个spider,名称为book
scrapy genspider book antispider7.scrape.center
定义Item,直接和详情页接口返回的字段一致即可,在item.py里面定义一个BookItem,代码如下:
from scrapy import Field, Item
class BookItem(Item):
authors = Field()
catalog = Field()
comments = Field()
cover = Field()
id = Field()
introduction = Field()
isbn = Field()
name = Field()
page_number = Field()
price = Field()
published_at = Field()
publisher = Field()
score = Field()
tags = Field()
translator = Field()
spider代码,在book.py中改写代码如下
from scrapy import Request, Spider
from ..items import BookItem
from loguru import logger
class BookSpider(Spider):
name = 'book'
allowed_domains = ['antispider7.scrape.center']
base_url = 'https://antispider7.scrape.center'
max_page = 512
def start_requests(self):
for page in range(1, self.max_page+1):
url = f'{self.base_url}/api/book/?limit=18&offset={(page-1)*18}'
yield Request(url, callback=self.parse_index)
def parse_index(self, res):
data = res.json()
results = data.get('results')
for result in results:
id = result.get('id')
url = f'{self.base_url}/api/book/{id}/'
yield Request(url, callback=self.parse_detail, priority=2) # priority表示该Requst在调度器中具有优先权
def parse_detail(self, res):
data = res.json()
item = BookItem()
for field in item.fields:
item[field] = data.get(field)
yield item
定时间隔设置为600s,用redis库的散列表实现,设置三个进程,分别是获取模块、测试模块、接口模块
from concurrent.futures import thread
from redis import StrictRedis
from requests import Session
import requests
from flask import Flask
import random
import time
import re
from multiprocessing import Process
url = 'https://antispider7.scrape.center/api/login'
url_center = 'https://antispider7.scrape.center/api/book/?limit=18&offset=0'
db = StrictRedis(host='localhost', port=6379, db=0,
decode_responses=True)
s = Session()
app = Flask(__name__)
def Getcookie(): # 没有cookie就获取cookie并填入
while True:
for username in db.hkeys('account'):
if not db.hexists('cookie', username):
r = s.post(url=url, data={'username': username,
'password': db.hget('account', username)})
# for cookie in s.cookies:
# result.append(f'{cookie.name}={cookie.value}')
# result = ';'.join(result)
print(r.status_code, username)
result = r.json().get('token', 'fail')
db.hset('cookie', username, result)
time.sleep(600)
def Testcookie(): # 根据res状态码把库中cookie无效的username键值对删除
while True:
if db.hgetall('cookie'):
print('exist')
else:
print('not exist')
db.hset('cookie', '1', '1')
print('已创建cookie')
for username, cookie in db.hgetall('cookie').items():
res = requests.get(
url_center, headers={'Authorization': f'jwt {cookie}'}, allow_redirects=False)
if res.status_code != 200:
db.hdel('cookie', username)
print('cookie', username, res.status_code, '已失效!')
else:
print('cookie', username, res.status_code, '可用!')
time.sleep(600)
@app.route('/') # 接口功能
def cookie_api():
result = db.hvals('cookie')
result = [i for i in result if i != '']
result = random.choice(result)
return result
def api():
app.run(threaded=True)
def schedule():
p1 = Process(target=Getcookie)
p2 = Process(target=Testcookie)
p3 = Process(target=api)
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
if __name__ == '__main__':
schedule()
购买快代理的隧道代理服务,结合上文的帐号池,在middlewares中添加如下代码:
import requests
class AuthorizationMiddleware():
accountpool_url = 'http://127.0.0.1:5000/'
tunnel = "tps656.kdlapi.com:15818"
username = "t15160185660737"
password = "vjopqphj"
proxies = "http://%(user)s:%(pwd)s@%(proxy)s/" % {
"user": username, "pwd": password, "proxy": tunnel}
def process_request(self, request, spider):
with requests.get(self.accountpool_url) as res:
authorization = res.text
authorization = f'jwt {authorization}'
request.headers['authorization'] = authorization # jwt认证参数加入
request.meta['proxy'] = self.proxies # 代理参数加入
from itemadapter import ItemAdapter
import pymongo
class ScrapycompositedemoPipeline:
def process_item(self, item, spider):
return item
class MongoDBPipeline(object):
@classmethod
def from_crawler(cls, crawler):
cls.connect_string = crawler.settings.get('MONGODB_CONNECTION_STRING')
cls.database = crawler.settings.get('MONGODB_DATABASE')
cls.collection = crawler.settings.get('MONGODB_COLLECTION')
return cls()
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.connect_string)
self.db = self.client[self.database]
def process_item(self, item, spider):
self.db[self.collection].update_one(
{'id': item['id']}, {'$set': dict(item)}, True)
return item
def close_spider(self, spider):
self.client.close()
ROBOTSTXT_OBEY = False # 不尊从robot协议
CONCURRENT_REQUESTS = 5 # 最大并发数
DOWNLOADER_MIDDLEWARES = {
'scrapycompositedemo.middlewares.AuthorizationMiddleware': 543 # 下载中间件的优先度设置,最小约靠近engine
}
RETRY_HTTP_CODES = [401, 403, 500, 502, 503, 504] # 重试情况,增加爬取成功率
DOWNLOAD_TIMEOUT = 10 # 请求超时设置
RETRY_TIMES = 10 # 重试次数设置
# mongodb常量设置
MONGODB_CONNECTION_STRING = 'localhost'
MONGODB_DATABASE = 'books'
MONGODB_COLLECTION = 'books'
ITEM_PIPELINES = {
'scrapycompositedemo.pipelines.MongoDBPipeline': 300 # 数据管道优先度设置,数字越小越靠近engine
}
最后,进行项目目录终端,运行如下代码:
scrapy crawl book
静待项目爬取完成。
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。





