

代码拉取完成,页面将自动刷新
tensorflow-cpu==2.2.0
import nets.mobilenet_v1 as net,配置选用的网络数据集
训练效果


- 神经网络和深度学习 (NNDL)
- 动手深度学习
- 深度学习实践:计算机视觉 (DLpCV)
- 复现实例参考:bubbling
- keras API
| Do? | ref. | Others | |
|---|---|---|---|
| LeNet-5 | × | 12 | |
| AlexNet | 12 | ||
| VGG | √ | 23 | |
| NiN | 2 | ||
| Inception_v1 | 123 | GoogLeNet | |
| ResNet | √ | 123 | |
| DenseNet | 23 | ||
| Xception | 3 | ||
| MobileNet_v1 | √ | 3 |
卷积神经网络

深度卷积神经网络
- 第一个现代深度卷积网络模型,首次使用了很多现代深度卷积网络的技术方法 e.g. 使用 GPU 进行并行训练,采用了 ReLU 作为非线性激活函数,使用Dropout方式过拟合,使用数据增强提高模型准确率
- 改进总结
- 与相对较小的LeNet相⽐, AlexNet包含8层变换,其中有5层卷积和2层全连接隐藏层,以 及1个全连接输出层
- AlexNet将sigmoid激活函数改成了更加简单的ReLU激活函数。
- AlexNet通过丢弃法(参⻅“丢弃法” ⼀节)来控制全连接层的模型复杂度。
- AlexNet引⼊了⼤量的图像增⼴,如翻转、裁剪和颜⾊变化,从而进⼀步扩⼤数据集来缓 解过拟合。

使用重复元素的网络
概念 AlexNet指明了深度卷积神经网络可以取得出色的结果,但并没有提供简单的规则以指导后来的研究者如何设计新的⽹络。
VGG提出了可以通过重复使用简单的基础块来构建深度模型的思路。
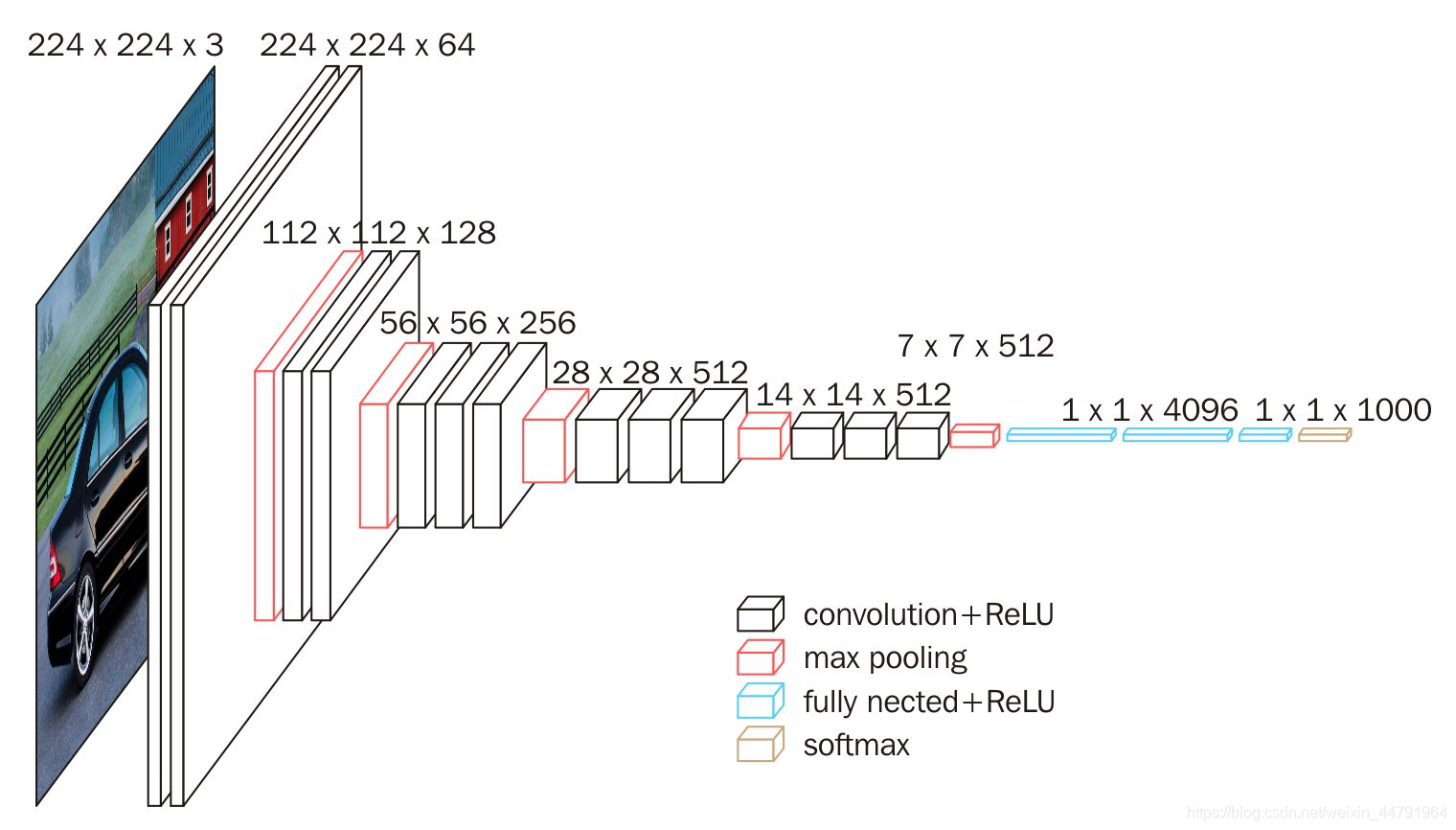
VGG
- VGG块的组成规律是: 连续使用数个相同的填充为1、窗口形状为 3×3 的卷积层后接上⼀个步幅为2、窗口形状为 2×2 的最大池化层。 卷积层保持输入的高和宽不变,而池化层则对其减半。
- 结构: 由卷积层模块后接全连接层模块构成。 卷积层模块串联数个vgg_block,其超参数由变量conv_arch定义。该变量指定了每个VGG块里卷积层个数和输出通道数。 全连接模块则与AlexNet中的一样。
- VGG-11
- VGG-16
- VGG-19

网络中的网络
- 概念 LeNet、 AlexNet和VGG在设计上的共同之处是:先以由卷积层构成的模块充分抽取空间特征,再以由全连接层构成的模块来输出分类结果。 NiN的思路:串联多个由卷积和全连接构成的小网络,来构建一个深层网络。
- NiN 模块 NiN使⽤1×1卷积层来替代全连接层,从而使空间信息能够⾃然传递到后⾯的层中去。
- 结构: NiN块是NiN中的基础块。它由⼀个卷积层加两个充当全连接层的1 × 1卷积层串联而成。其中第⼀个卷积层的超参数可自行设置,而第二、三个卷积层的超参数⼀般是固定的。
- NiN
- NiN是在AlexNet问世不久后提出的。它们的卷积层设定有类似之处。 NiN使用卷积窗口形状分别为11×11、5×5和3×3的卷积层,相应的输出通道数也与AlexNet中的一致。每个NiN块后接一个步幅为2、窗口形状为3×3的最大池化层。
- 除使⽤NiN块以外, NiN还有⼀个设计与AlexNet显著不同: NiN去掉了AlexNet最后的3个全连接层,取而代之地, NiN使⽤了输出通道数等于标签类别数的NiN块,然后使⽤全局平均池化层对每个通道中所有元素求平均并直接⽤于分类。这⾥的全局平均池化层即窗口形状等于输⼊空间维形状的平均池化层。 NiN的这个设计的好处是可以显著减小模型参数尺⼨,从而缓解过拟合。然而,该设计有时会造成获得有效模型的训练时间的增加。

含并行连接的网络
Inception 模块 一个卷积层包含多个不同大小的卷积操作, 称为 Inception 模块 Inception网络是由有多个Inception模块和少量的汇聚层堆叠而成
Inception_v1 总共为22层网络 —— 由9个 Inception v1 模块和5个汇聚层以及其他一些卷积层和 全连接层构成
其他 为了解决梯度消失问题, GoogLeNet 在网络中间层引入两个辅助分类器来加强监督信息
改进版本 有多个改进版本,其中比较有代表性的有 Inception_v3 网络[Szegedy et al., 2016]
Inception v3 网络用多层的小卷积核来替换大的卷积核,以减少计算量和参数量, 并保持感受野不变 具体包括: 1) 使用两层3 × 3的卷积来替换v1中的5 × 5的卷积; 2) 使用连续的𝐾 × 1和1 × 𝐾 来替换𝐾 × 𝐾 的卷积.此外, Inception v3网络同时也引入了标签平滑以及批量归一化等优化方法进行训练。
另:Inception_v3 对下采样过程中的特征提取做了组合,常规的操作一般是卷积再池化或池化后再卷积;Inception_v3则是将这一步做了分支,使得网络变宽。在35×35到17×17到8×8的下采样过程中,会用到这种特征融合结构。
Inception_v4 则吸收了ResNet思想。传统ResNet使用的是CNN的结构,那么将CNN的结构换成Inception的基本结构则形成了Inception_v4版本。其他变种还有Inception_ResNet_v1 和 Inception_ResNet_v2 两个版本。
另:
- 吸收了NiN中网络串联网络的思想,并在此基础上做了很大改进。
- 网络的基础结构都是模块,但 Inception 模块 比 NiN 模块 在结构上更加复杂。

清晰图见 https://nndl.github.io/v/cnn-googlenet

残差网络
概念 通过给非线性的卷积层增加直连边(Shortcut Connection)(也称为残差连接(Residual Connection)) 的方式来提高信息的传播效率
Residual Block 残差模块
Conv Block 输入和输出的维度是不一样的,所以不能连续串联,它的作用是改变网络的维度
Conv Block可以分为两个部分,左边部分为主干部分,存在两次卷积、标准化、激活函数和一次卷积、标准化;右边部分为残差边部分,存在一次卷积、标准化,由于残差边部分存在卷积,所以我们可以利用Conv Block改变输出特征层的宽高和通道数
Identity Block 输入维度和输出维度相同,可以串联,用于加深网络的
Identity Block可以分为两个部分,左边部分为主干部分,存在两次卷积、标准化、激活函数和一次卷积、标准化;右边部分为残差边部分,直接与输出相接,由于残差边部分不存在卷积,所以Identity Block的输入特征层和输出特征层的shape是相同的,可用于加深网络
ResNet
- ResNet_50 详细结构图
- ResNet_101
- ResNet_152




稠密连接网络
DenseNet的主要构建模块是稠密块(dense block)和过渡层(transition layer)
- Dense Block 稠密模块 DenseNet使⽤了ResNet改良版的“批量归⼀化、激活和卷积”结构
- Transition Layer 过渡层 由于每个稠密块都会带来通道数的增加,使⽤过多则会带来过于复杂的模型。过渡层⽤来控制模型复杂度。它通过1 × 1卷积层来减小通道数,并使⽤步幅为2的平均池化层减半⾼和宽,从而进⼀步降低模型复杂度。

移动版本
MobilenetV1模型是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,其使用的核心思想便是depthwise separable convolution(深度可分离卷积块)。
- 深度可分离卷积块
- 深度可分离卷积块由两个部分组成,分别是深度可分离卷积和1x1普通卷积,深度可分离卷积的卷积核大小一般是3x3的,便于理解的话我们可以把它当作是特征提取,1x1的普通卷积可以完成通道数的调整。
- 深度可分离卷积块的目的是使用更少的参数来代替普通的3x3卷积。
- 对比普通卷积和深度可分离卷积块
- 对于普通卷积而言,假设有一个3×3大小的卷积层,其输入通道为16、输出通道为32。具体为,32个3×3大小的卷积核会遍历16个通道中的每个数据,最后可得到所需的32个输出通道,所需参数为16×32×3×3=4608个。
- 对于深度可分离卷积结构块而言,假设有一个深度可分离卷积结构块,其输入通道为16、输出通道为32,其会用16个3×3大小的卷积核分别遍历16通道的数据,得到了16个特征图谱。在融合操作之前,接着用32个1×1大小的卷积核遍历这16个特征图谱,所需参数为16×3×3+16×32×1×1=656个。

略。
略。
参考:[Keras API reference / Keras Applications](Keras Applications)


此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。







