

代码拉取完成,页面将自动刷新
本地缓存是在同一个进程内的内存空间中缓存数据,数据读写都是在同一个进程内完成;而分布式缓存是一个独立部署的进程并且一般都是与应用进程部署在不同的机器,故需要通过网络来完成分布式缓存数据读写操作的数据传输。相对于分布式缓存,本地缓存访问速度快,但存在不支持大数据量存储、数据更新时不好保证各节点数据一致性、数据随应用进程的重启而丢失的缺点。
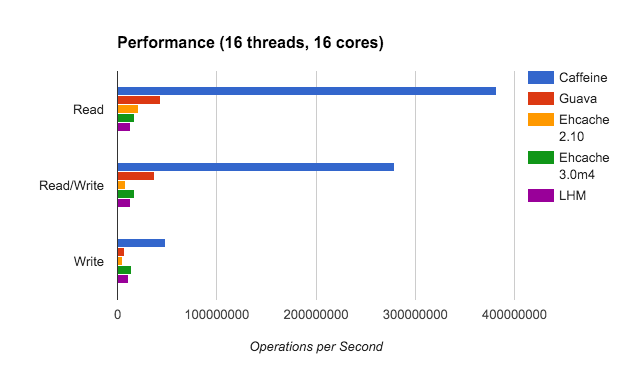
Guava Cache的功能强大、提供的Api容易使用,但其本质上仍然是对LRU算法的封装,在缓存命中率上是存在天生缺陷的。Caffeine提出了一种更高效的近似LFU准入策略的缓存结构TinyLFU及其变种W-TinyLFU,并借鉴Guava Cache的设计经验,得到了功能强大且性能更优的新一代本地缓存。
如何保证分布式节点一级缓存的一致性?
保证本地缓存在分布式环境的一致性可见以下几种方法:
1.设置过期时间:在对某个key进行修改或删除时,同时更新缓存中该key的失效时间。当其他节点访问该key时,发现缓存已经过期,则从数据源中获取最新数据,并更新自己的一级缓存。
2.消息发布/订阅:在多个节点之间建立发布/订阅通道,当某个节点对某个key进行修改或删除时,通过通道发布相应的消息,订阅的其他节点接收到消息后,更新自己的一级缓存。
3.使用分布式缓存:使用分布式缓存系统,如Redis集群或Memcached集群,可以将缓存数据分布在多个节点上。这样,在对某个key进行修改或删除时,可以通过分布式缓存提供的相应API进行操作,以保持多个节点的一级缓存一致。
本项目基于Redis消息发布/订阅实现了分布式节点的缓存一致性。
1.将项目模块redis-caffeine-spring-boot-autoconfigure内容导入到自己文件,可根据需要对内容进行更改
2.引入模块
<dependency>
<groupId>org.cache</groupId>
<artifactId>redis-caffeine-spring-boot-autoconfigure</artifactId>
<version>1.0.0</version>
</dependency>
3.根据application-dev.properties文件内容进行自己需要的配置
4.启动类加上@EnableCaching
5.在需要缓存的方法上增加@Cacheable注解
@Cacheable(key = "'cache_user_id_' + #id", value = "userIdCache", cacheManager = "cacheManager", sync = true)
public UserVO get(long id) {
logger.info("get by id from db");
UserVO user = new UserVO();
user.setId(id);
user.setName("name" + id);
user.setCreateTime(TimestampUtil.current());
return user;
}
如果对您有帮助,请点个star!
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。






