

代码拉取完成,页面将自动刷新
English |  中文 
🤗 Hugging Face • 🤖 魔搭 ModelScope • ✡️ 始智 WiseModel
👩🚀 欢迎来 GitHub Discussions 讨论问题
👋 欢迎加入 👾 Discord 或者 💬 微信群 一起交流
📝 欢迎查阅 Yi 技术报告 了解更多
📚 欢迎来 Yi 学习中心 探索新知
🤖 Yi 系列模型是 01.AI 从零训练的下一代开源大语言模型。
🙌 Yi 系列模型是一个双语语言模型,在 3T 多语言语料库上训练而成,是全球最强大的大语言模型之一。Yi 系列模型在语言认知、常识推理、阅读理解等方面表现优异。例如,
Yi-34B-Chat 模型在 AlpacaEval Leaderboard 排名第二,仅次于 GPT-4 Turbo,超过了 GPT-4、Mixtral 和 Claude 等大语言模型(数据截止至 2024 年 1 月)。
Yi-34B 模型在 Hugging Face Open LLM Leaderboard(预训练)与 C-Eval 基准测试中荣登榜首,在中文和英文语言能力方面均超过了其它开源模型,例如,Falcon-180B、Llama-70B 和 Claude(数据截止至 2023 年 11 月)。
🙏 (致谢 Llama )感谢 Transformer 和 Llama 开源社区,不仅简化了开发者从零开始构建大模型的工作,开发者还可以利用 Llama 生态中现有的工具、库和资源,提高开发效率。
💡 简短总结
Yi 系列模型采用与Llama相同的模型架构,但它们不是 Llama 的衍生品。
Yi 和 Llama 都是基于 Transformer 结构。实际上,自 2018 年以来,Transformer 一直是大语言模型的常用架构。
在 Transformer 架构的基础上,Llama 凭借出色的稳定性、可靠的收敛性和强大的兼容性,成为大多数先进开源模型的基石。因此,Llama 也成为 Yi 等模型的基础框架。
得益于 Transformer 和 Llama 架构,各类模型可以简化从零开始构建模型的工作,并能够在各自的生态中使用相同的工具。
然而,Yi 系列模型不是 Llama 的衍生品,因为它们不使用 Llama 的权重。
虽然大多数开源模型都采用了 Llama 的架构,但决定模型表现的关键因素是训练所使用的数据集、训练管道及其基础设施。
01.AI 用独特的方式开发了 Yi 系列模型,从零开始创建了自己的高质量训练数据集、高效的训练流水线和强大的训练基础设施,因此 Yi 系列模型性能优异,在 Alpaca Leaderboard 上排名仅次于 GPT-4,超过了 Llama(数据截止至 2023 年 12 月)。
[ 返回顶部 ⬆️ ]
Yi-9B-200K 模型。Yi-9B 模型。Yi-9B 模型在 Mistral-7B、SOLAR-10.7B、Gemma-7B、DeepSeek-Coder-7B-Base-v1.5 等相近尺寸的模型中名列前茅,具有出色的代码能力、数学能力、常识推理能力以及阅读理解能力。
Yi-VL-34B 和 Yi-VL-6B 多模态语言大模型。Yi-VL-34B在 MMMU 和 CMMMU 最新的基准测试中荣登榜首(数据截止至 2024 年 1 月)。
Yi-34B-ChatYi-34B-Chat-4bitsYi-34B-Chat-8bitsYi-6B-ChatYi-6B-Chat-4bitsYi-6B-Chat-8bitsYi-6B-200K 和 Yi-34B-200K Base 模型。 Yi-6B-Base 和 Yi-34B-Base 模型。[ 返回顶部 ⬆️ ]
Yi 系列模型有多种参数规模,适用于不同的使用场景。你也可以对Yi模型进行微调,从而满足特定需求。
如需部署 Yi 系列模型,应确保软件和硬件满足「部署要求」.
| 模型 | 下载 |
|---|---|
| Yi-34B-Chat | • 🤗 Hugging Face • 🤖 ModelScope |
| Yi-34B-Chat-4bits | • 🤗 Hugging Face • 🤖 ModelScope |
| Yi-34B-Chat-8bits | • 🤗 Hugging Face • 🤖 ModelScope |
| Yi-6B-Chat | • 🤗 Hugging Face • 🤖 ModelScope |
| Yi-6B-Chat-4bits | • 🤗 Hugging Face • 🤖 ModelScope |
| Yi-6B-Chat-8bits | • 🤗 Hugging Face • 🤖 ModelScope |
- 4-bits 系列模型由AWQ量化。
- 8-bits 系列模型由GPTQ量化。
- 所有量化模型的使用门槛较低,因此可以在消费级GPU(例如,3090、4090)上部署。
| 模型 | 下载 |
|---|---|
| Yi-34B | • 🤗 Hugging Face • 🤖 ModelScope |
| Yi-34B-200K | • 🤗 Hugging Face • 🤖 ModelScope |
| Yi-9B | • 🤗 Hugging Face • 🤖 ModelScope |
| Yi-9B-200K | • 🤗 Hugging Face • 🤖 ModelScope |
| Yi-6B | • 🤗 Hugging Face • 🤖 ModelScope |
| Yi-6B-200K | • 🤗 Hugging Face • 🤖 ModelScope |
- 200K 大约相当于 40 万个汉字。
- 如果你想用 Yi-34B-200K 更早的版本 (即 2023 年 11 月 5 日发布的版本),可以运行代码 git checkout 069cd341d60f4ce4b07ec394e82b79e94f656cf,下载权重。
Model | Intro | 默认的上下文窗口 | 预训练的 tokens 数量 | 训练数据
| Model | Intro | 默认的上下文窗口 | 预训练的 tokens 数量 | 训练数据 |
|---|---|---|---|---|
| 6B 系列模型 | 适合个人和学术使用。 | 4K | 3T | 截至 2023 年 6 月。 |
| 9B 系列模型 | 是 Yi 系列模型中代码和数学能力最强的模型。 | Yi-9B 是在 Yi-6B 的基础上,使用了 0.8T tokens 进行继续训练。 | ||
| 34B 系列模型 | 适合个人、学术和商业用途(尤其对中小型企业友好)。 34B 模型尺寸在开源社区属于稀缺的“黄金比例”尺寸,已具大模型涌现能力,适合发挥于多元场景,满足开源社区的刚性需求。 |
3T |
Chat 模型
注意,回复多样化也可能会导致某些已知问题更加严重,例如,
[ 返回顶部 ⬆️ ]
你可以选择一条学习路径,开始使用 Yi 系列模型。
你可以根据自身需求,选择以下方式之一,开始你的 Yi 之旅。
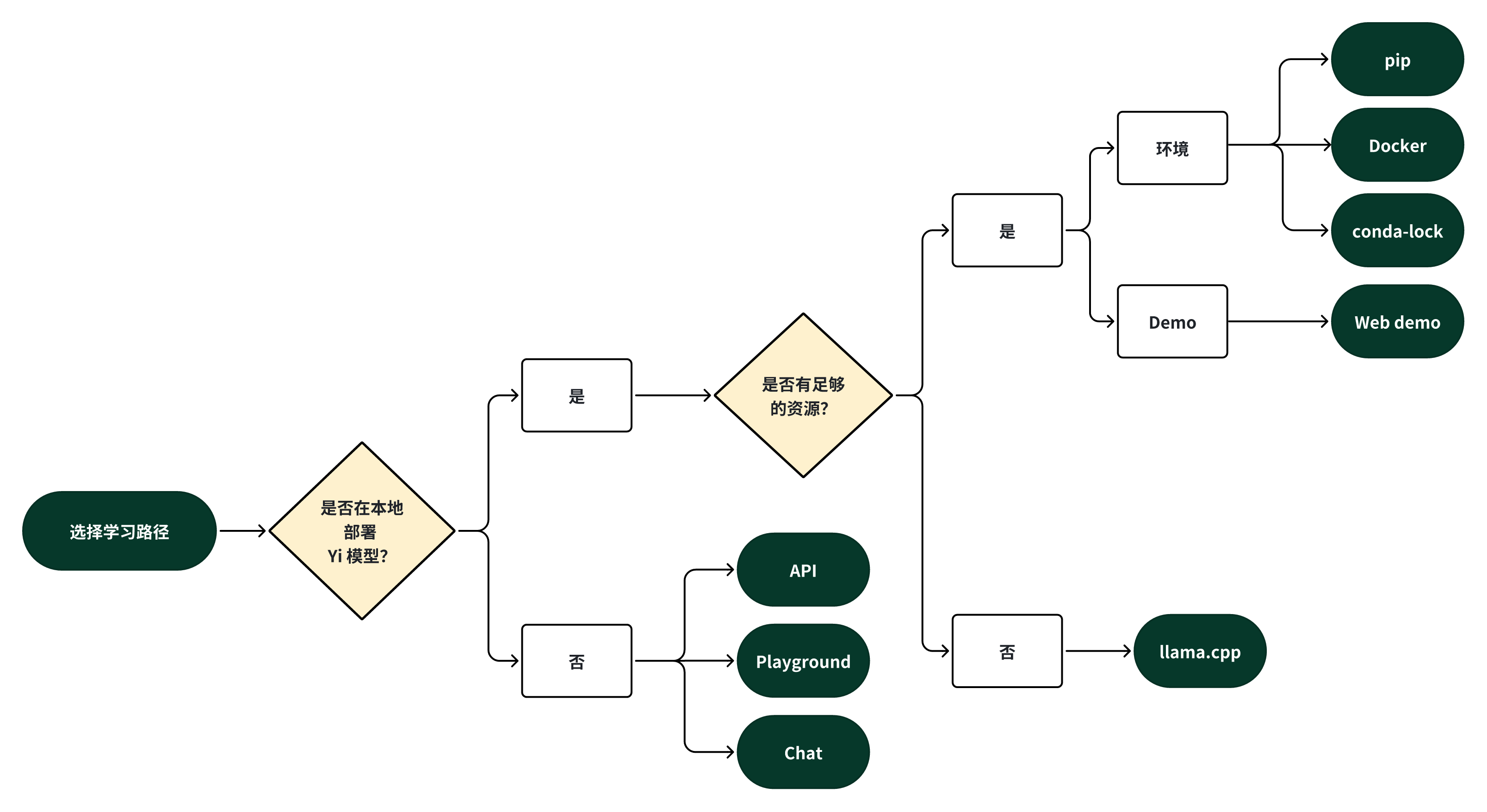
如果你想在本地部署 Yi 模型,
如果你不想在本地部署 Yi 模型,你可以选择以下方式之一。
如果你想探索 Yi 的更多功能,你可以选择以下方式之一。
如果你想与 Yi 聊天,并使用更多自定义选项(例如,系统提示、温度、重复惩罚等),你可以选择以下方式之一。
Yi-34B-Chat-Playground (Yi 官方)
Yi-34B-Chat-Playground (Replicate,第三方网站)
以下提供了类似的用户体验,你可以选择以下方式之一,与 Yi 聊天。
Yi-34B-Chat(Yi 官方 - Hugging Face)
Yi-34B-Chat(Yi 官方)
[ 返回顶部 ⬆️ ]
本教程在配置为 A800(80GB) 的本地机器上运行 Yi-34B-Chat, 并进行推理。
确保安装了 Python 3.10 以上版本。
如果你想运行 Yi 系列模型,参阅「部署要求」。
如需设置环境,安装所需要的软件包,运行下面的命令。
git clone https://github.com/01-ai/Yi.git
cd yi
pip install -r requirements.txt
你可以从以下来源下载 Yi 模型。
你可以使用 Yi Chat 模型或 Base 模型进行推理。
创建一个名为 quick_start.py 的文件,并将以下内容复制到该文件中。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = '<your-model-path>'
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
# Since transformers 4.35.0, the GPT-Q/AWQ model can be loaded using AutoModelForCausalLM.
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype='auto'
).eval()
# Prompt content: "hi"
messages = [
{"role": "user", "content": "hi"}
]
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids.to('cuda'))
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
# Model response: "Hello! How can I assist you today?"
print(response)
运行 quick_start.py 代码。
python quick_start.py
你将得到一个类似输出,如下所示。🥳
Hello! How can I assist you today?
步骤与「使用 Yi Chat 模型进行推理」类似。
你可以使用现有文件 text_generation.py进行推理。
python demo/text_generation.py --model <your-model-path>
指令: Let me tell you an interesting story about cat Tom and mouse Jerry,
回复: Let me tell you an interesting story about cat Tom and mouse Jerry, which happened in my childhood. My father had a big house with two cats living inside it to kill mice. One day when I was playing at home alone, I found one of the tomcats lying on his back near our kitchen door, looking very much like he wanted something from us but couldn’t get up because there were too many people around him! He kept trying for several minutes before finally giving up...
Yi-9B
输入
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_DIR = "01-ai/Yi-9B"
model = AutoModelForCausalLM.from_pretrained(MODEL_DIR, torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR, use_fast=False)
input_text = "# write the quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=256)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
输出
# write the quick sort algorithm
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
# test the quick sort algorithm
print(quick_sort([3, 6, 8, 10, 1, 2, 1]))
[ 返回顶部 ⬆️ ]
[ 返回顶部 ⬆️ ]
确保你已经安装了 Docker 和 nvidia-container-toolkit。
docker run -it --gpus all \
-v <your-model-path>: /models
ghcr.io/01-ai/yi:latest
或者,你也可以从registry.lingyiwanwu.com/ci/01-ai/yi:latest 拉取已经构建好的 Yi Docker 镜像。
你可以使用 Yi 的 Chat 模型或 Base 模型进行推理。
进行推理的步骤与「 在 pip 上使用 Yi Chat 模型进行推理 」类似。
注意: 唯一不同的是你需要设置 model_path 为 = '<your-model-mount-path>' 而不是 = '<your-model-path>'。
进行推理的步骤与「 在 pip 上使用 Yi Chat 模型进行推理 」类似。
注意: 唯一不同的是你需要设置 model_path 为 = '<your-model-mount-path>' 而不是 = '<your-model-path>'。
conda-lock 工具。 ⬇️micromamba工具来安装这些依赖项。
根据指南安装 "micromamba"。
运行命令 micromamba install -y -n yi -f conda-lock.yml ,创建一个名为yi conda 环境,并安装所需的依赖项。
该教程适用于 MacBook Pro(16GB 内存和 Apple M2 Pro 芯片)。
确保你的电脑上安装了 git-lfs 。
llama.cpp
如需克隆 llama.cpp 仓库,运行以下命令。
git clone git@github.com:ggerganov/llama.cpp.git
步骤 2.1:仅下载 XeIaso/yi-chat-6B-GGUF 仓库的 pointers,运行以下命令。
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/XeIaso/yi-chat-6B-GGUF
步骤 2.2:下载量化后的 Yi 模型 yi-chat-6b.Q2_K.gguf,运行以下命令。
git-lfs pull --include yi-chat-6b.Q2_K.gguf
如需体验 Yi 模型(运行模型推理),你可以选择以下方式之一。
[方式 2:在 Web上进行推理](#方式-2在 Web上进行推理)
本文使用 4 个线程编译 llama.cpp ,之后进行推理。在 llama.cpp 所在的目录,运行以下命令。
提示
将
/Users/yu/yi-chat-6B-GGUF/yi-chat-6b.Q2_K.gguf替换为你的模型的实际路径。默认情况下,模型是续写模式(completion mode)。
如需查看更多自定义选项(例如,系统提示、温度、重复惩罚等),运行
./main -h查看详细使用说明。
make -j4 && ./main -m /Users/yu/yi-chat-6B-GGUF/yi-chat-6b.Q2_K.gguf -p "How do you feed your pet fox? Please answer this question in 6 simple steps:\nStep 1:" -n 384 -e
...
How do you feed your pet fox? Please answer this question in 6 simple steps:
Step 1: Select the appropriate food for your pet fox. You should choose high-quality, balanced prey items that are suitable for their unique dietary needs. These could include live or frozen mice, rats, pigeons, or other small mammals, as well as fresh fruits and vegetables.
Step 2: Feed your pet fox once or twice a day, depending on the species and its individual preferences. Always ensure that they have access to fresh water throughout the day.
Step 3: Provide an appropriate environment for your pet fox. Ensure it has a comfortable place to rest, plenty of space to move around, and opportunities to play and exercise.
Step 4: Socialize your pet with other animals if possible. Interactions with other creatures can help them develop social skills and prevent boredom or stress.
Step 5: Regularly check for signs of illness or discomfort in your fox. Be prepared to provide veterinary care as needed, especially for common issues such as parasites, dental health problems, or infections.
Step 6: Educate yourself about the needs of your pet fox and be aware of any potential risks or concerns that could affect their well-being. Regularly consult with a veterinarian to ensure you are providing the best care.
...
恭喜你!你已经成功地向 Yi 模型提出了问题,得到了回复!🥳
如需启用一个轻便敏捷的聊天机器人,你可以运行以下命令。
./server --ctx-size 2048 --host 0.0.0.0 --n-gpu-layers 64 --model /Users/yu/yi-chat-6B-GGUF/yi-chat-6b.Q2_K.gguf
你将得到一个类似输出。
...
llama_new_context_with_model: n_ctx = 2048
llama_new_context_with_model: freq_base = 5000000.0
llama_new_context_with_model: freq_scale = 1
ggml_metal_init: allocating
ggml_metal_init: found device: Apple M2 Pro
ggml_metal_init: picking default device: Apple M2 Pro
ggml_metal_init: ggml.metallib not found, loading from source
ggml_metal_init: GGML_METAL_PATH_RESOURCES = nil
ggml_metal_init: loading '/Users/yu/llama.cpp/ggml-metal.metal'
ggml_metal_init: GPU name: Apple M2 Pro
ggml_metal_init: GPU family: MTLGPUFamilyApple8 (1008)
ggml_metal_init: hasUnifiedMemory = true
ggml_metal_init: recommendedMaxWorkingSetSize = 11453.25 MB
ggml_metal_init: maxTransferRate = built-in GPU
ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 128.00 MiB, ( 2629.44 / 10922.67)
llama_new_context_with_model: KV self size = 128.00 MiB, K (f16): 64.00 MiB, V (f16): 64.00 MiB
ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 0.02 MiB, ( 2629.45 / 10922.67)
llama_build_graph: non-view tensors processed: 676/676
llama_new_context_with_model: compute buffer total size = 159.19 MiB
ggml_backend_metal_buffer_type_alloc_buffer: allocated buffer, size = 156.02 MiB, ( 2785.45 / 10922.67)
Available slots:
-> Slot 0 - max context: 2048
llama server listening at http://0.0.0.0:8080
如需访问聊天机器人界面,可以打开网络浏览器,在地址栏中输入 http://0.0.0.0:8080。

如果你在提示窗口中输入问题,例如,“如何喂养你的宠物狐狸?请用 6 个简单的步骤回答”,你将收到类似的回复。

[ 返回顶部 ⬆️ ]
你可以使用 Yi Chat 模型(Yi-34B-Chat)创建 Web demo。 注意:Yi Base 模型(Yi-34B)不支持该功能。
第三步:启动 Web demo 服务,运行以下命令。
python demo/web_demo.py -c <你的模型路径>
命令运行完毕后,你可以在浏览器中输入控制台提供的网址,来使用 Web demo 功能。

[ 返回顶部 ⬆️ ]
bash finetune/scripts/run_sft_Yi_6b.sh
完成后,你可以使用以下命令,比较微调后的模型与 Base 模型。
bash finetune/scripts/run_eval.sh
默认情况下,我们使用来自BAAI/COIG 的小型数据集来微调 Base 模型。
你还可以按照以下 jsonl 格式准备自定义数据集。
{ "prompt": "Human: Who are you? Assistant:", "chosen": "I'm Yi." }
然后将自定义数据集挂载到容器中,替换默认数据。
docker run -it \
-v /path/to/save/finetuned/model/:/finetuned-model \
-v /path/to/train.jsonl:/yi/finetune/data/train.json \
-v /path/to/eval.jsonl:/yi/finetune/data/eval.json \
ghcr.io/01-ai/yi:latest \
bash finetune/scripts/run_sft_Yi_6b.sh
确保你已经安装了 conda。如需安装 conda, 你可以运行以下命令。
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
~/miniconda3/bin/conda init bash
source ~/.bashrc
然后,创建一个 conda 环境。
conda create -n dev_env python=3.10 -y
conda activate dev_env
pip install torch==2.0.1 deepspeed==0.10 tensorboard transformers datasets sentencepiece accelerate ray==2.7
如果你想使用 Yi-6B 模型,建议使用具有 4 个 GPU 的节点,每个 GPU 内存大于 60GB。
如果你想使用 Yi-34B 模型,注意此模式采用零卸载技术,占用了大量 CPU 内存,因此需要限制 34B 微调训练中的 GPU 数量。你可以使用 CUDA_VISIBLE_DEVICES 限制 GPU 数量(如 scripts/run_sft_Yi_34b.sh 中所示)。
用于微调 34B 模型的常用硬件具有 8 个 GPU 的节点(通过CUDA_VISIBLE_DEVICES=0,1,2,3 在运行中限制为4个 GPU),每个 GPU 的内存大于 80GB,总 CPU 内存大于900GB。
将 LLM-base 模型下载到 MODEL_PATH(6B 和 34B)。模型常见的文件夹结构如下。
|-- $MODEL_PATH
| |-- config.json
| |-- pytorch_model-00001-of-00002.bin
| |-- pytorch_model-00002-of-00002.bin
| |-- pytorch_model.bin.index.json
| |-- tokenizer_config.json
| |-- tokenizer.model
| |-- ...
将数据集从 Hugging Face 下载到本地存储 DATA_PATH,例如, Dahoas/rm-static。
|-- $DATA_PATH
| |-- data
| | |-- train-00000-of-00001-2a1df75c6bce91ab.parquet
| | |-- test-00000-of-00001-8c7c51afc6d45980.parquet
| |-- dataset_infos.json
| |-- README.md
finetune/yi_example_dataset 中有示例数据集,这些数据集是从 BAAI/COIG修改而来。
|-- $DATA_PATH
|--data
|-- train.jsonl
|-- eval.jsonl
cd 进入 scripts 文件夹,复制并粘贴脚本,然后运行。你可以使用以下代码完成此项。
cd finetune/scripts
bash run_sft_Yi_6b.sh
对于 Yi-6B-Base 模型,设置 training_debug_steps=20 和 num_train_epochs=4, 就可以输出一个 Chat 模型,大约需要 20 分钟。
对于 Yi-34B-Base 模型,初始化时间相对较长,请耐心等待。
cd finetune/scripts
bash run_eval.sh
你将得到 Base 模型和微调模型的回复。
[ 返回顶部 ⬆️ ]
python quantization/gptq/quant_autogptq.py \
--model /base_model \
--output_dir /quantized_model \
--trust_remote_code
如需评估生成的模型,你可以使用以下代码。
python quantization/gptq/eval_quantized_model.py \
--model /quantized_model \
--trust_remote_code
GPT-Q 是一种后训练量化方法,能够帮助大型语言模型在使用时节省内存,保持模型的准确性,并加快模型的运行速度。
如需对 Yi 模型进行 GPT-Q 量化,使用以下教程。
运行 GPT-Q 需要使用 AutoGPTQ 和 exllama。 此外,Hugging Face Transformers 已经集成了 optimum 和 auto-gptq,能够实现语言模型的 GPT-Q 量化。
如需量化模型,你可以使用以下 quant_autogptq.py 脚本。
python quant_autogptq.py --model /base_model \
--output_dir /quantized_model --bits 4 --group_size 128 --trust_remote_code
如需运行量化模型,你可以使用以下 eval_quantized_model.py 脚本。
python eval_quantized_model.py --model /quantized_model --trust_remote_code
python quantization/awq/quant_autoawq.py \
--model /base_model \
--output_dir /quantized_model \
--trust_remote_code
如需评估生成的模型,你可以使用以下代码。
python quantization/awq/eval_quantized_model.py \
--model /quantized_model \
--trust_remote_code
AWQ是一种后训练量化方法,可以将模型的权重数据高效准确地转化成低位数据(例如,INT3 或 INT4),因此可以减小模型占用的内存空间,保持模型的准确性。
如需对 Yi 模型进行 AWQ 量化,你可以使用以下教程。
运行 AWQ 需要使用 AutoAWQ。
如需量化模型,你可以使用以下 quant_autoawq.py 脚本。
python quant_autoawq.py --model /base_model \
--output_dir /quantized_model --bits 4 --group_size 128 --trust_remote_code
如需运行量化模型,你可以使用以下 eval_quantized_model.py 脚本。
python eval_quantized_model.py --model /quantized_model --trust_remote_code
[ 返回顶部 ⬆️ ]
如果你想部署 Yi 模型,确保满足以下软件和硬件要求。
在使用 Yi 量化模型之前,确保安装以下软件。
| 模型 | 软件 |
|---|---|
| Yi 4-bits 量化模型 | AWQ 和 CUDA |
| Yi 8-bits 量化模型 | GPTQ 和 CUDA |
部署 Yi 系列模型之前,确保硬件满足以下要求。
| 模型 | 最低显存 | 推荐 GPU 示例 |
|---|---|---|
| Yi-6B-Chat | 15 GB | 1 x RTX 3090 (24 GB) 1 x RTX 4090 (24 GB) 1 x A10 (24 GB) 1 x A30 (24 GB) |
| Yi-6B-Chat-4bits | 4 GB | 1 x RTX 3060 (12 GB) 1 x RTX 4060 (8 GB) |
| Yi-6B-Chat-8bits | 8 GB | 1 x RTX 3070 (8 GB) 1 x RTX 4060 (8 GB) |
| Yi-34B-Chat | 72 GB | 4 x RTX 4090 (24 GB) 1 x A800 (80GB) |
| Yi-34B-Chat-4bits | 20 GB | 1 x RTX 3090 (24 GB) 1 x RTX 4090 (24 GB) 1 x A10 (24 GB) 1 x A30 (24 GB) 1 x A100 (40 GB) |
| Yi-34B-Chat-8bits | 38 GB | 2 x RTX 3090 (24 GB) 2 x RTX 4090 (24 GB) 1 x A800 (40 GB) |
以下是不同 batch 使用情况下的最低显存要求。
| 模型 | batch=1 | batch=4 | batch=16 | batch=32 |
|---|---|---|---|---|
| Yi-6B-Chat | 12 GB | 13 GB | 15 GB | 18 GB |
| Yi-6B-Chat-4bits | 4 GB | 5 GB | 7 GB | 10 GB |
| Yi-6B-Chat-8bits | 7 GB | 8 GB | 10 GB | 14 GB |
| Yi-34B-Chat | 65 GB | 68 GB | 76 GB | > 80 GB |
| Yi-34B-Chat-4bits | 19 GB | 20 GB | 30 GB | 40 GB |
| Yi-34B-Chat-8bits | 35 GB | 37 GB | 46 GB | 58 GB |
| 模型 | 最低显存 | 推荐GPU示例 |
|---|---|---|
| Yi-6B | 15 GB | 1 x RTX 3090 (24 GB) 1 x RTX 4090 (24 GB) 1 x A10 (24 GB) 1 x A30 (24 GB) |
| Yi-6B-200K | 50 GB | 1 x A800 (80 GB) |
| Yi-9B | 20 GB | 1 x RTX 4090 (24 GB) |
| Yi-34B | 72 GB | 4 x RTX 4090 (24 GB) 1 x A800 (80 GB) |
| Yi-34B-200K | 200 GB | 4 x A800 (80 GB) |
我可以在哪里获取微调的问答数据集?
Yi-34B FP16 的微调需要多少 GPU 内存?
进行 34B FP16 的微调,所需的 GPU 内存量取决于具体的微调方式。进行全参数微调,需要 8 张 80 GB的显卡;而Lora 等低资源方案,需要的资源较少。你可以参考 hiyouga/LLaMA-Factory,获取更多信息。同时,建议你使用 BF16 代替 FP16 来进行微调,优化性能。
Yi-34b-200k 有第三方 Chat 平台吗?
如果你想访问第三方 Chat,可以选择人工智能平台 fireworks.ai。
欢迎来到 Yi 学习中心!
无论你是经验丰富的专家还是初出茅庐的新手,你都可以在这里找到丰富的学习资源,增长有关 Yi 模型的知识,提升相关技能。这里的博客文章具有深刻的见解,视频教程内容全面,实践指南可实操性强,这些学习资源都可以助你一臂之力。
感谢各位 Yi 专家和用户分享了许多深度的技术内容,我们对各位小伙伴的宝贵贡献表示衷心的感谢!
在此,我们也热烈邀请你加入我们,为 Yi 做出贡献。如果你创作了关于 Yi 系列模型的内容,欢迎提交 PR 分享!🙌
有了这些学习资源,你可以立即开启 Yi 学习之旅。祝学习愉快!🥳
| 类型 | 教程 | 日期 | 作者 |
|---|---|---|---|
| 博客 | Running Yi-34B-Chat locally using LlamaEdge | 2023-11-30 | Second State |
| 视频 | Install Yi 34B Locally - Chinese English Bilingual LLM | 2023-11-05 | Fahd Mirza |
| 视频 | Dolphin Yi 34b - Brand New Foundational Model TESTED | 2023-11-27 | Matthew Berman |
| 类型 | 教程 | 日期 | 作者 |
|---|---|---|---|
| GitHub 项目 | 基于零一万物 Yi 模型和 B 站构建大语言模型高质量训练数据集 | 2024-04-29 | 正经人王同学 |
| GitHub 项目 | 基于视频网站和零一万物大模型构建大语言模型高质量训练数据集 | 2024-04-25 | 正经人王同学 |
| 博客 | 基于零一万物yi-vl-plus大模型简单几步就能批量生成Anki图片笔记 | 2024-04-24 | 正经人王同学 |
| GitHub 项目 | 基于零一万物yi-34b-chat-200k输入任意文章地址,点击按钮即可生成无广告或推广内容的简要笔记,并生成分享图给好友 | 2024-04-24 | 正经人王同学 |
| 博客 | 实测零一万物Yi-VL多模态语言模型:能准确“识图吃瓜” | 2024-02-02 | 苏洋 |
| 博客 | 本地运行零一万物 34B 大模型,使用 LLaMA.cpp & 21G 显存 | 2023-11-26 | 苏洋 |
| 博客 | 零一万物模型折腾笔记:官方 Yi-34B 模型基础使用 | 2023-12-10 | 苏洋 |
| 博客 | CPU 混合推理,非常见大模型量化方案:“二三五六” 位量化方案 | 2023-12-12 | 苏洋 |
| 博客 | 单卡 3 小时训练 Yi-6B 大模型 Agent:基于 LLaMA Factory 实战 | 2024-01-22 | 郑耀威 |
| 博客 | 零一万物开源Yi-VL多模态大模型,魔搭社区推理&微调最佳实践来啦! | 2024-01-26 | ModelScope |
| 视频 | 只需 24G 显存,用 vllm 跑起来 Yi-34B 中英双语大模型 | 2023-12-28 | 漆妮妮 |
| 视频 | Yi-VL-34B 多模态大模型 - 用两张 A40 显卡跑起来 | 2023-01-28 | 漆妮妮 |
Yi 生态为你提供一系列工具、服务和模型,你将获得丰富的体验,最大程度提升工作工作效率。
Yi 系列模型遵循与 Llama 相同的模型架构。选择 Yi,你可以利用 Llama 生态中现有的工具、库和资源,无需创建新工具,提高开发效率。
例如,Yi 系列模型以 Llama 模型的格式保存。你可以直接使用 LlamaForCausalLM 和 LlamaTokenizer 加载模型,使用以下代码。
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("01-ai/Yi-34b", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("01-ai/Yi-34b", device_map="auto")
[ 返回顶部 ⬆️ ]
💡 提示
如果你开发了与 Yi 相关的服务、模型、工具、平台或其它内容,欢迎提交 PR,将你的成果展示在 Yi 生态。
为了帮助他人快速理解你的工作,建议使用
<模型名称>: <模型简介> + <模型亮点>的格式。
如果你想在几分钟内开始使用 Yi,你可以使用以下基于 Yi 构建的服务。
Yi-34B-Chat:你可以通过以下平台与 Yi 聊天。
Yi-6B-Chat (Replicate):使用该工具,你可以设置自定义参数,调用 APIs 来使用 Yi-6B-Chat。
ScaleLLM:你可以使用该工具在本地运行 Yi 模型,根据自身偏好进行个性化设置。
如果资源有限,你可以使用 Yi 的量化模型,如下所示。
这些量化模型虽然精度降低,但效率更高,例如,推理速度更快,RAM 使用量更小。
如果你希望探索 Yi 的其它微调模型,你可以尝试以下方式。
TheBloke 模型:该网站提供了大量微调模型,这些微调模型基于多种大语言模型,包括 Yi 模型。
以下是 Yi 的微调模型,根据下载量排序,包括但不限于以下模型。
SUSTech/SUS-Chat-34B:该模型在所有 70B 以下的模型中排名第一,超越了体量是其两倍的 deepseek-llm-67b-chat。你可以在 Open LLM Leaderboard 上查看结果。
OrionStarAI/OrionStar-Yi-34B-Chat-Llama:该模型在 C-Eval 和 CMMLU 评估中超越了其它模型(例如,GPT-4、Qwen-14B-Chat 和 Baichuan2-13B-Chat),在 OpenCompass LLM Leaderboard 上表现出色。
NousResearch/Nous-Capybara-34B:该模型在 Capybara 数据集上使用 200K 上下文长度和 3 个 epochs 进行训练。
[ 返回顶部 ⬆️ ]
Yi-34B-Chat 模型表现出色,在 MMLU、CMMLU、BBH、GSM8k 等所有开源模型的基准测试中排名第一。

*: C-Eval 的结果来源于验证数据集。
Yi-34B 和 Yi-34B-200K 模型在开源模型中脱颖而出,尤其在 MMLU、CMMLU、常识推理、阅读理解等方面表现卓越。

Yi-9B 模型在 Mistral-7B、SOLAR-10.7B、Gemma-7B、DeepSeek-Coder-7B-Base-v1.5 等相近尺寸的模型中名列前茅,具有出色的代码能力、数学能力、常识推理能力以及阅读理解能力。

在综合能力方面(Mean-All),Yi-9B 的性能在尺寸相近的开源模型中最好,超越了 DeepSeek-Coder、DeepSeek-Math、Mistral-7B、SOLAR-10.7B 和 Gemma-7B。

在代码能力方面(Mean-Code),Yi-9B 的性能仅次于 DeepSeek-Coder-7B,超越了 Yi-34B、SOLAR-10.7B、Mistral-7B 和 Gemma-7B。

在数学能力方面(Mean-Math),Yi-9B 的性能仅次于 DeepSeek-Math-7B,超越了 SOLAR-10.7B、Mistral-7B 和 Gemma-7B。

在常识和推理能力方面(Mean-Text),Yi-9B 的性能与 Mistral-7B、SOLAR-10.7B 和 Gemma-7B 不相上下。

[ 返回顶部 ⬆️ ]
更多关于 Yi 系列模型性能的详细信息,参阅 「Yi:Open Foundation Models by 01.AI」。
@misc{ai2024yi,
title={Yi: Open Foundation Models by 01.AI},
author={01. AI and : and Alex Young and Bei Chen and Chao Li and Chengen Huang and Ge Zhang and Guanwei Zhang and Heng Li and Jiangcheng Zhu and Jianqun Chen and Jing Chang and Kaidong Yu and Peng Liu and Qiang Liu and Shawn Yue and Senbin Yang and Shiming Yang and Tao Yu and Wen Xie and Wenhao Huang and Xiaohui Hu and Xiaoyi Ren and Xinyao Niu and Pengcheng Nie and Yuchi Xu and Yudong Liu and Yue Wang and Yuxuan Cai and Zhenyu Gu and Zhiyuan Liu and Zonghong Dai},
year={2024},
eprint={2403.04652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
答案是所有人! 🙌 ✅
关于如何使用 Yi 系列模型,参阅「许可证」。
[ 返回顶部 ⬆️ ]
我们对每位火炬手都深表感激,感谢你们为 Yi 社区所做的贡献。因为有你们,Yi 不仅是一个项目,还成为了一个充满活力的创新社区。我们由衷地感谢各位小伙伴!
Yi Readme 中文版由以下贡献者完成,排名不分先后,以用户名首字母顺序排列。
[ 返回顶部 ⬆️ ]
在训练过程中,我们使用数据合规性检查算法,最大程度地确保训练模型的合规性。由于数据复杂且语言模型使用场景多样,我们无法保证模型在所有场景下均能生成正确合理的回复。注意,模型仍可能生成有误的回复。对于任何因误用、误导、非法使用、错误使用导致的风险和问题,以及与之相关的数据安全问题,我们均不承担责任。
[ 返回顶部 ⬆️ ]
本仓库中的源代码遵循 Apache 2.0 许可证。
[ 返回顶部 ⬆️ ]
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。







